
The AI Benchmark Gauntlet: Decoding the Race for Supremacy Beyond GPT-4
The relentless pace of artificial intelligence development has created a dynamic and fiercely competitive landscape. Scarcely a week goes by without major GPT Models News, announcing a new model that claims to dethrone the reigning champions. Central to these announcements is the concept of the benchmark—a standardized test designed to measure and compare the cognitive abilities of different AI systems. As new contenders emerge to challenge established leaders like OpenAI’s GPT-4, understanding the nuances of these benchmarks is more critical than ever. This constant cycle of one-upmanship, fueled by impressive scores on leaderboards, is not just about bragging rights; it shapes developer adoption, enterprise investment, and the very trajectory of GPT Future News.
This article delves deep into the world of GPT Benchmark News, moving beyond the headlines to explore what these metrics truly represent. We will dissect the most common benchmarks, analyze their strengths and weaknesses, and discuss the profound implications for developers, businesses, and the entire GPT Ecosystem. The race for AI supremacy is not just a numbers game; it’s a complex interplay of capability, availability, efficiency, and real-world applicability. Navigating this landscape requires a critical eye and a comprehensive understanding of the forces at play.
The Anatomy of an AI Benchmark Showdown
In the rapidly evolving AI arena, benchmarks serve as the de facto yardstick for progress. They provide a quantitative, seemingly objective way to compare models that are, by nature, complex and multifaceted. This reliance on standardized testing has turned every major model release into a high-stakes event, heavily influencing GPT Competitors News and market perception.
What Are AI Benchmarks and Why Do They Matter?
AI benchmarks are standardized tasks or datasets designed to evaluate specific capabilities of a model. They are crucial for researchers to track progress and for developers to choose the right tool for their needs. Some of the most frequently cited benchmarks include:
- MMLU (Massive Multitask Language Understanding): A comprehensive test covering 57 subjects, from elementary mathematics to US history and professional law, designed to measure a model’s general knowledge and problem-solving ability.
- HumanEval: A benchmark focused on coding proficiency. It consists of 164 programming problems that test a model’s ability to generate functionally correct code from docstrings. This is a key metric in GPT Code Models News.
- GSM8K (Grade School Math 8K): A dataset of high-quality, grade-school-level math word problems that require multi-step reasoning to solve. It’s a key indicator of a model’s logical reasoning capabilities.
- HellaSwag: A commonsense reasoning benchmark that challenges models to complete a sentence by choosing the most plausible ending from a list of options.
These benchmarks dominate OpenAI GPT News and competitor announcements because they offer a quick, digestible way to communicate a model’s advancements. A high MMLU score suggests broad intelligence, while a top HumanEval score signals powerful capabilities for software development, directly impacting GPT Applications News.
The Current Landscape: A Battle for the Top Spot
The current AI landscape is characterized by a constant battle for the top position on these leaderboards. For a long time, models in the GPT-4 class set the standard, but the market is no longer monolithic. We are seeing a new wave of models from various labs, each claiming state-of-the-art (SOTA) performance on one or more key benchmarks. This intense competition is a major driver of GPT Trends News, pushing the boundaries of what’s possible in AI. The news cycle is filled with claims of “beating GPT-4,” which, while exciting, requires careful scrutiny from the community. This competition also fuels innovation in GPT Architecture News and GPT Training Techniques News as companies seek an edge.
Beyond the Leaderboard: A Critical Analysis of Performance Metrics
While benchmarks are indispensable tools, relying solely on leaderboard scores can be misleading. A model’s true value is a combination of its quantitative scores and its qualitative performance in real-world scenarios. A critical analysis reveals the limitations of our current evaluation methods and points toward a more holistic approach.
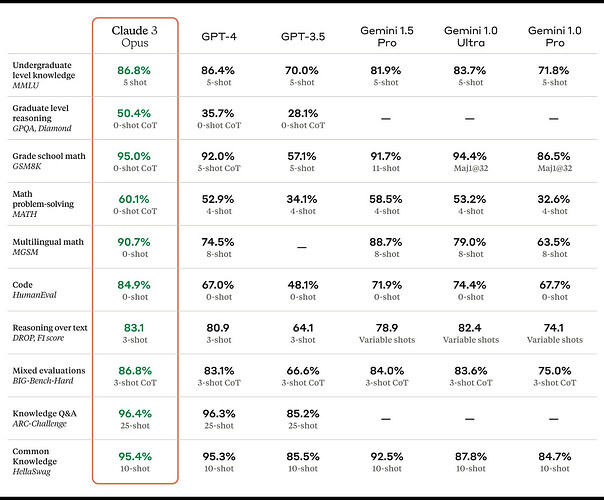
The Pitfall of “Teaching to the Test”
A significant concern in the AI community is benchmark contamination. This occurs when data from a benchmark’s test set inadvertently leaks into a model’s training data. The result is a model that has “memorized” the answers rather than learning the underlying reasoning skills the benchmark is supposed to measure. This leads to inflated scores that don’t reflect true general intelligence. As a result, there is a growing focus in GPT Research News on creating new, “unseen” benchmarks and developing more robust evaluation methodologies. This issue highlights the importance of understanding the GPT Datasets News associated with a model’s training.
Quantitative Scores vs. Qualitative Experience
A model can achieve a SOTA score on a benchmark but still provide a frustrating user experience. Qualitative aspects are harder to measure but are often more important for practical applications:
- Alignment and Safety: How well does the model adhere to instructions and safety guidelines? A high benchmark score is meaningless if the model is prone to generating harmful, biased, or nonsensical content. This is a central topic in GPT Ethics News and GPT Safety News.
- Creativity and Nuance: Can the model generate truly creative text, understand subtle humor, or adopt a specific tone of voice? These capabilities are not well-captured by multiple-choice benchmarks but are vital for GPT in Creativity News and GPT in Content Creation News.
- Bias and Fairness: Does the model exhibit biases present in its training data? Addressing this is a major focus of GPT Bias & Fairness News and is critical for deploying AI in sensitive areas like finance or healthcare.
Real-World Application Benchmarks
To address the shortcomings of abstract benchmarks, there is a growing trend toward creating industry-specific evaluation suites. For example, a model’s performance in GPT in Healthcare News might be judged on its ability to accurately summarize patient notes or interpret medical imaging reports. Similarly, GPT in Legal Tech News focuses on benchmarks for contract analysis and legal research. These real-world tests provide a much clearer picture of a model’s utility for a specific job, moving beyond generic intelligence scores to measure tangible value.
Implications for the Broader GPT Ecosystem
The relentless pursuit of benchmark supremacy has far-reaching consequences, influencing everything from hardware development to API adoption and the very structure of the AI market.
Driving Innovation in Architecture and Efficiency
The race to the top is a powerful catalyst for innovation. Researchers are constantly experimenting with new architectures, such as Mixture-of-Experts (MoE), to build more powerful and efficient models. This focus on performance extends beyond raw intelligence to include operational efficiency. Significant research is being poured into techniques like quantization and distillation, which are central to GPT Compression News and GPT Quantization News. These methods aim to reduce the computational cost and memory footprint of models, making them more accessible for GPT Deployment News, especially on edge devices, a key topic in GPT Edge News. The hardware itself is also evolving, with GPT Hardware News frequently highlighting new chips optimized for AI inference.
The Developer’s Dilemma: Choosing the Right API
For developers, every major benchmark announcement presents a choice. Does the new SOTA model warrant switching from an existing, trusted API? The answer is complex. While raw performance is a factor, developers must also consider:

- Latency and Throughput: How fast is the model’s response time? For real-time applications like GPT Chatbots News or GPT Assistants News, low latency is non-negotiable. This is a core concern in GPT Inference News.
- Cost: What is the price per token? A model that is 5% better but 50% more expensive may not be a viable choice for many applications.
- Stability and Documentation: Is the API reliable? Is it well-documented and supported? These factors are critical for production-grade systems and are a key part of GPT APIs News.
This decision-making process is shaping the competitive dynamics among GPT Platforms News and driving providers to compete not just on performance, but on the overall developer experience.
The Rise of Specialized and Multimodal Models
The benchmark race has also highlighted that a single “one-size-fits-all” model may not be the optimal solution. This has led to the rise of specialized models fine-tuned for specific domains. We are seeing a surge in GPT Code Models News, with models that outperform generalists in software development tasks. Simultaneously, the field is moving towards multimodality. The latest GPT Multimodal News and GPT Vision News showcase models that can understand and process text, images, and audio simultaneously, opening up a vast new range of applications from analyzing medical scans to creating interactive gaming experiences, a topic of interest in GPT in Gaming News.
Practical Considerations for Evaluating and Adopting New Models
Navigating the hype cycle of AI benchmark news requires a pragmatic and strategic approach. For businesses and developers looking to leverage the latest advancements, it’s essential to look beyond the headlines and conduct a thorough evaluation.
Best Practices for Evaluation
When a new model claims to be the best, don’t take the claim at face value. Implement a structured evaluation process:
- Define Your Use Case: Identify the specific tasks you need the AI to perform. A model that excels at creative writing may not be the best for data extraction.
- Run a Pilot Program: Test the new model on a small scale with your own data and workflows. Compare its output directly against your current solution.
- Measure What Matters: Go beyond standard benchmarks. Measure metrics relevant to your business, such as user satisfaction, task completion rate, or reduction in manual effort. This is crucial for evaluating GPT Applications in IoT News or GPT in Finance News.
- Consider Total Cost of Ownership: Factor in API costs, integration effort, and potential maintenance. The cheapest model isn’t always the most cost-effective in the long run.
The Availability vs. Capability Trade-off
A critical consideration is the model’s availability. A new model that achieves groundbreaking benchmark scores but is only accessible through a limited preview or a research paper is of little immediate use to the broader developer community. An established, slightly less performant model with a robust, scalable, and globally available API often provides more immediate value. The true “thunder” of a new model is not just its potential capability but its actual, practical availability to build with today.
Common Pitfalls to Avoid
Avoid making hasty decisions based on marketing announcements. A common pitfall is to immediately begin re-architecting systems around a new, unproven model. This can lead to wasted engineering effort if the model doesn’t live up to its hype or if the provider’s API is unstable. It’s wiser to adopt a flexible architecture that allows for swapping out different models, enabling you to leverage the best technology as it becomes mature and reliable. Keep an eye on GPT Regulation News and GPT Privacy News, as these factors can also impact the long-term viability of a model provider.
Conclusion
The world of GPT Benchmark News is an exhilarating, fast-paced theater of innovation. The constant competition to top the leaderboards is undeniably accelerating progress in AI, pushing the boundaries of what these powerful systems can achieve. However, as consumers of this technology, it is our responsibility to look beyond the scores. Benchmarks are a vital starting point, but they are not the final word on a model’s worth.
A truly comprehensive evaluation must consider qualitative performance, real-world applicability, cost, latency, and availability. The most successful AI implementations will come from those who can critically analyze the news, test new models against their unique needs, and make strategic decisions based on a holistic understanding of the technology. The race for AI supremacy will continue to produce astonishing results, and by maintaining a balanced and informed perspective, we can effectively harness these advancements to build the next generation of intelligent applications.


