
Revolutionizing Clinical Trials: A Technical Deep Dive into GPT-3.5 vs. GPT-4 for Patient Recruitment
The pharmaceutical and medical research industries have long faced a persistent, billion-dollar bottleneck: clinical trial recruitment. Historically, identifying eligible patients for specific studies has been a manual, labor-intensive process fraught with delays and human error. However, the landscape of GPT in Healthcare News is shifting rapidly. With the advent of Large Language Models (LLMs), specifically OpenAI’s GPT-3.5 and its more advanced successor, GPT-4, the methodology for screening patient records is undergoing a digital transformation.
While GPT-3.5 News initially highlighted the potential for generative AI to assist in administrative tasks, the emergence of GPT-4 News has introduced a higher level of reasoning capability necessary for complex medical decision support. This article explores the technical nuances, performance metrics, and implementation strategies of using these models for clinical trial matching. We will examine how these tools parse unstructured Electronic Health Records (EHRs), the specific advantages of GPT-4 over its predecessor, and the critical ethical considerations required when deploying AI in Healthcare.
Section 1: The Evolution of Automated Recruitment in Clinical Research
The Challenge of Unstructured Data
To understand the significance of GPT Models News in this sector, one must first understand the data problem. Clinical trial protocols contain rigorous inclusion and exclusion criteria—complex logic statements defining who can participate (e.g., “Patients with Stage III carcinoma, excluding those with a history of cardiac arrhythmia within the last 6 months”). Conversely, patient data lives in EHRs, which are notoriously unstructured. While demographics might be structured, critical nuances are often buried in free-text clinician notes.
Traditional Natural Language Processing (NLP) struggled with context. A keyword search for “arrhythmia” might flag a patient as ineligible even if the note says “Patient has no history of arrhythmia.” This is where the semantic understanding of modern Transformers comes into play.
From GPT-3.5 to GPT-4: A Leap in Reasoning
When GPT-3.5 News first broke, it demonstrated a remarkable ability to generate human-like text and perform basic logic tasks. It offered a cost-effective solution for summarizing patient notes and extracting entities. However, clinical trial matching requires more than just extraction; it requires multi-step reasoning.
GPT-4 News heralded a significant upgrade in GPT Architecture News. With a larger parameter count and improved training reinforcement, GPT-4 demonstrates superior capabilities in handling complex negations, temporal reasoning (understanding timeframes like “within the last 6 months”), and conditional logic. In the context of GPT Research News, studies are increasingly showing that while GPT-3.5 is a capable assistant, GPT-4 acts more like a junior resident, capable of synthesizing disparate pieces of information to form a coherent eligibility conclusion.
The Role of Context Windows
Another critical factor discussed in GPT Tokenization News is the context window. Medical records can be lengthy. The expanded context windows available in newer API versions allow for the ingestion of comprehensive patient histories without aggressive truncation, ensuring that vital contraindications hidden deep in a patient’s history are not overlooked.
Section 2: Technical Analysis: GPT-3.5 vs. GPT-4 in Patient Screening
Comparative Performance Metrics

When evaluating GPT Benchmark News regarding clinical extraction, the distinction between the two models becomes clear. In head-to-head comparisons for identifying eligible patients:
- Sensitivity and Specificity: GPT-4 consistently outperforms GPT-3.5 in specificity. GPT-3.5 has a higher tendency for “hallucination” or false positives—flagging a patient as eligible when a subtle exclusion criterion should have disqualified them.
- Complex Logic Handling: In scenarios involving double negatives or conditional dependencies (e.g., “Eligible only if X is present AND Y is absent”), GPT-3.5 often struggles, defaulting to keyword association. GPT-4 demonstrates a stronger grasp of boolean logic embedded in natural language.
- Zero-Shot vs. Few-Shot: GPT Training Techniques News suggests that GPT-4 performs remarkably well in zero-shot environments (no examples provided), whereas GPT-3.5 often requires few-shot prompting (providing examples of correct matches) to achieve acceptable accuracy in medical contexts.
Cost-Benefit Analysis and Latency
Despite the superior intelligence of the newer model, GPT-3.5 News remains relevant due to GPT Efficiency News. GPT-3.5 Turbo is significantly faster and cheaper than GPT-4. For high-volume, low-complexity screening (e.g., initial filtering based on age, gender, and primary diagnosis), GPT-3.5 is the optimal choice.
However, for the “last mile” of recruitment—analyzing complex oncology notes or rare disease pathology reports—the higher cost and GPT Latency & Throughput News associated with GPT-4 are justifiable expenses. The cost of a failed screen in a clinical trial is astronomical compared to the fraction of a cent per token charged by GPT APIs News.
Real-World Scenario: The Oncology Trial
Consider a trial for a new immunotherapy drug. The criteria exclude patients with “active autoimmune disease requiring systemic treatment in the past two years.”
The Data: A patient note reads: “Patient has a history of rheumatoid arthritis, currently in remission, last flare-up treated with prednisone three years ago.”
- GPT-3.5 Analysis: Might flag “rheumatoid arthritis” and “prednisone” and incorrectly classify the patient as ineligible due to the presence of autoimmune keywords.
- GPT-4 Analysis: Correctly identifies the temporal aspect (“three years ago” is outside the “past two years” window) and the status (“remission”), correctly classifying the patient as potentially eligible.
This nuance highlights why GPT Optimization News focuses heavily on reasoning capabilities for high-stakes verticals like healthcare.
Section 3: Implementation Strategies and Best Practices
Integration via APIs and Privacy
Implementing these models requires robust engineering. GPT Integrations News indicates that leading health-tech companies are not using ChatGPT via the web interface but are integrating via secure APIs (like Azure OpenAI Service) to ensure HIPAA compliance. GPT Privacy News is paramount here; data must be encrypted, and enterprises must ensure their data is not used to train the base models.
Prompt Engineering for Clinical Accuracy
To maximize the utility of OpenAI GPT News updates, developers must master prompt engineering. Best practices include:
- Chain-of-Thought Prompting: Instruct the model to “think step-by-step” and cite the specific text in the EHR that supports its eligibility decision. This aids in verification.
- Structured Output: Request the output in JSON format. This aligns with GPT Tools News, allowing the AI’s decision to be easily ingested by downstream clinical trial management systems (CTMS).
- Role-Playing: defining the system message as “You are an expert clinical research coordinator.”
The Hybrid Approach: RAG (Retrieval-Augmented Generation)
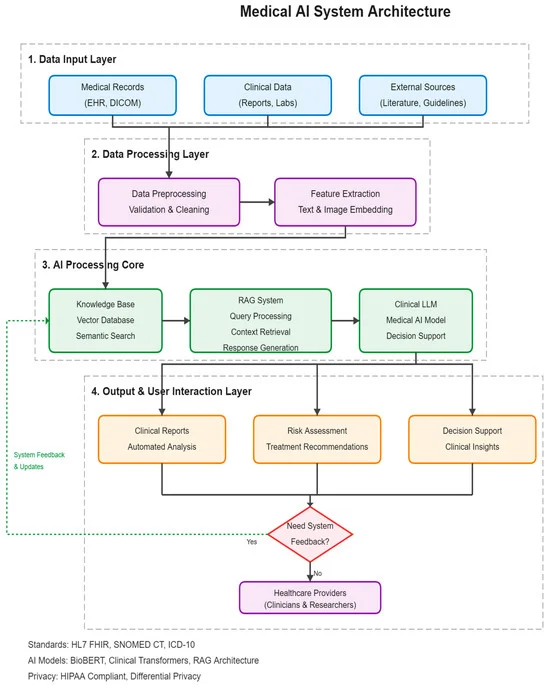
GPT Custom Models News and GPT Fine-Tuning News often spark debates on whether to train a model on medical data. However, the current consensus in GPT Deployment News favors Retrieval-Augmented Generation (RAG). By indexing patient records in a vector database and retrieving only relevant chunks to feed into the GPT context window, systems can reduce hallucinations and improve traceability. This approach leverages the reasoning of the model without the massive overhead of fine-tuning.
The Human-in-the-Loop Necessity
Regardless of the model used, GPT Safety News dictates that AI cannot be the final arbiter. The output of these models should serve as a recommendation engine for clinical staff, highlighting probable candidates and citing evidence. This reduces the manual review time from hours to minutes but maintains the necessary clinician oversight required by GPT Regulation News.
Section 4: Implications, Ethics, and the Future Landscape
Bias and Fairness
A critical area of GPT Bias & Fairness News involves the demographic data present in training sets. If the underlying models have biases regarding how symptoms are described in different demographics, the recruitment tool could inadvertently exclude underrepresented populations. Continuous auditing of the AI’s decisions across different demographic groups is essential to ensure equitable trial access.
Multimodal Capabilities
Looking forward, GPT Multimodal News and GPT Vision News are opening new frontiers. Future iterations could analyze medical imaging (CT scans, MRIs) alongside text notes to determine eligibility based on tumor size or progression, strictly following RECIST criteria. This moves beyond text processing into comprehensive diagnostic analysis.

The Rise of Agents
GPT Agents News suggests a future where autonomous agents don’t just screen patients but actively query databases, schedule appointments, and answer patient questions about the protocol. These GPT Assistants News tools could revolutionize the patient experience, making participation in trials less burdensome.
Regulatory Landscape
As GPT Competitors News heats up with models like Claude or Gemini entering the space, regulators (FDA, EMA) are scrutinizing AI in Healthcare. We can expect stricter guidelines on GPT Open Source News versus proprietary models in clinical settings, focusing on reproducibility and explainability. The “black box” nature of deep learning is a hurdle that GPT Research News is actively trying to solve through interpretability studies.
Conclusion
The integration of Large Language Models into clinical trial recruitment represents a paradigm shift in medical research. While GPT-3.5 News introduced the world to the possibilities of generative text, GPT-4 News has provided the reasoning capabilities necessary to handle the complexity of medical data. By automating the pre-screening process, these tools can drastically reduce the time and cost associated with drug development, ultimately bringing life-saving therapies to market faster.
However, this power comes with responsibility. The distinction in performance between GPT-3.5 and GPT-4 highlights the need for selecting the right tool for the task—balancing GPT Efficiency News with the need for high-stakes accuracy. Furthermore, as we look toward GPT-5 News and beyond, the industry must remain vigilant regarding GPT Ethics News, data privacy, and the absolute necessity of human oversight. AI is not replacing the clinician; it is empowering them to focus on what matters most: the patient.
Stay tuned for more GPT Trends News and updates on how GPT Applications News are reshaping the future of digital health.
Related Posts

Inside GPT Mixture-of-Experts Routing

Inside the BPE Tokenizer: How GPT Splits Words Into Subword Units
