
Beyond Billions of Parameters: A Deep Dive into GPT Scaling, MoE, and the Future of AI
The Next Frontier in AI: Unpacking the Latest GPT Scaling News and What It Means for the Future
The relentless pace of innovation in artificial intelligence, particularly within the realm of Large Language Models (LLMs), continues to capture global attention. For years, the prevailing narrative in GPT Models News was simple: bigger is better. The race to scale models from millions to billions, and now trillions, of parameters defined the cutting edge. However, the latest GPT Scaling News reveals a significant paradigm shift. The conversation is evolving from brute-force scaling to a more nuanced, intelligent approach focused on architectural innovation and computational efficiency.
Breakthroughs in areas like Mixture of Experts (MoE) and advanced Reinforcement Learning (RL) techniques are redefining what it means to build a state-of-the-art model. This isn’t just an academic exercise; these advancements have profound implications for everything from the future of ChatGPT News to the development of next-generation GPT Agents News. This article delves into the technical underpinnings of these new scaling strategies, explores their real-world impact across industries, and analyzes the critical challenges and ethical considerations that accompany this new era of AI development. We’ll unpack the trends shaping GPT-4 News and provide a glimpse into the much-anticipated GPT-5 News.
The Shifting Paradigm: From Brute Force to Intelligent Scaling
The journey of GPT models has been a masterclass in the power of scale. However, the traditional approach of building ever-larger “dense” models is hitting practical and economic walls. This has forced a pivot towards more sophisticated architectures that promise greater capability without a proportional increase in computational cost.
The Limits of Dense Models
Early models like GPT-3 demonstrated a clear correlation between parameter count and performance, a phenomenon described by “scaling laws.” A dense model activates all of its parameters for every single token it processes. While effective, scaling this approach indefinitely leads to staggering challenges. The training costs become astronomical, requiring massive clusters of specialized hardware, a key topic in GPT Hardware News. Furthermore, inference—the process of using the trained model—becomes slow and expensive, directly impacting GPT Latency & Throughput News. The latest OpenAI GPT News and research from competitors suggest that while scaling laws still hold, the industry is actively seeking more efficient ways to achieve greater intelligence, moving beyond the simple metrics that dominated GPT-3.5 News.
Enter Mixture of Experts (MoE): The New Architecture
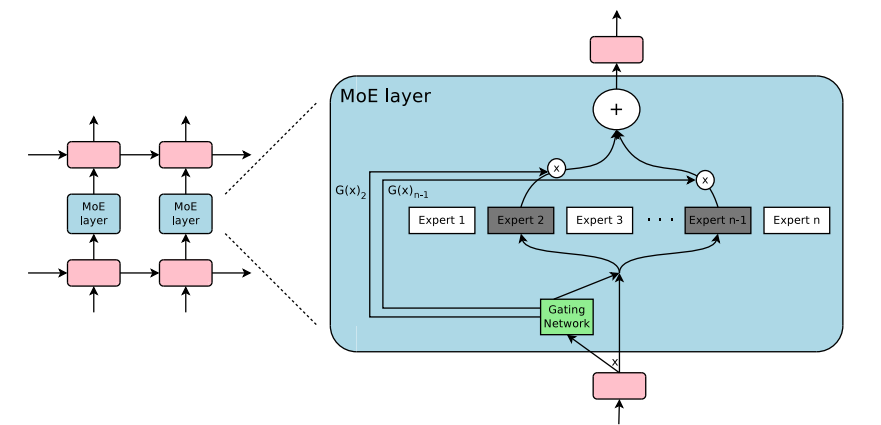
A leading solution to the dense model dilemma is the Mixture of Experts (MoE) architecture. Imagine a dense model as a single, massive brain where every neuron fires for every thought. An MoE model, in contrast, is like a committee of specialized experts. For any given task or piece of information (a token), a “routing network” intelligently selects a small subset of relevant experts to handle the computation. This is a revolutionary piece of GPT Architecture News. A model can have trillions of total parameters, but only a fraction—perhaps a few hundred billion—are activated during inference. This provides the knowledge capacity of a massive model with the computational cost of a much smaller one, a critical development for GPT Inference News and overall GPT Efficiency News.
The Crucial Role of Reinforcement Learning
Scaling isn’t just about architecture; it’s also about control. As models become more powerful, ensuring they are aligned with human intent is paramount. This is where advanced GPT Training Techniques News, particularly Reinforcement Learning from Human Feedback (RLHF), becomes indispensable. RLHF is used to fine-tune models to be more helpful, harmless, and honest. As we scale towards more capable systems, RL is being used not just for alignment but to teach models complex reasoning and tool-use capabilities. This synergy between massive, efficient architectures and sophisticated training methods is what will unlock the true potential of future systems and is a core focus of GPT Research News.

Technical Deep Dive: The Mechanics of Modern Scaling
Understanding the shift in scaling strategy requires a closer look at the underlying technologies. These innovations are not just theoretical; they are actively being implemented, benchmarked, and deployed, shaping the entire GPT Ecosystem News.
How Mixture of Experts (MoE) Truly Works
At its core, an MoE layer replaces a standard feed-forward network in the Transformer architecture. It consists of two key components: a set of “expert” networks (which are themselves smaller neural networks) and a “gating” or “routing” network. When a token is processed, the gating network calculates a probability distribution over the experts, deciding which one or two are best suited for that specific token. This dynamic, token-level routing is the magic of MoE. However, it introduces unique training challenges. A primary one is load balancing—ensuring that all experts receive a roughly equal amount of training to prevent some from becoming over-specialized while others are neglected. This requires sophisticated algorithms and is a hot topic for those following GPT Training Techniques News and the development of specialized GPT Inference Engines.
Optimizing for Efficiency: Beyond Parameter Count
Scaling intelligently also means making models leaner and faster post-training. Several key optimization techniques are now standard practice:
- GPT Quantization News: This involves reducing the numerical precision of the model’s weights (e.g., from 32-bit floating-point numbers to 8-bit integers). This dramatically shrinks the model’s memory footprint and speeds up computation, making it feasible to run powerful models on less robust hardware, a key aspect of GPT Edge News.
- GPT Distillation News: In this “student-teacher” approach, a large, powerful “teacher” model is used to train a much smaller “student” model. The student learns to mimic the teacher’s output distribution, effectively inheriting its capabilities in a more compact form.
- GPT Compression News: This includes techniques like pruning, where redundant or unimportant connections within the neural network are removed, further reducing model size and improving GPT Inference News metrics. The efficacy of these methods is constantly tracked in GPT Benchmark News.
The Synergy of Multimodality
The future of scaling is not just textual. The latest GPT Multimodal News highlights the integration of different data types into a single, unified model. Architectures are being developed to process text, images, audio, and video simultaneously. MoE is particularly well-suited for this, as different experts can specialize in different modalities. For example, a model might route visual information to a set of “vision experts” and textual information to “language experts,” allowing them to collaborate to understand complex, multi-faceted inputs. This is the technology behind the incredible capabilities discussed in GPT Vision News and is central to creating more context-aware and human-like AI assistants.
Implications and the Expanding Ecosystem: From APIs to Agents
These advanced scaling techniques are not confined to research labs. They are actively reshaping the digital landscape, empowering developers, creating new business models, and transforming entire industries.
Impact on Developers and GPT APIs
For developers, this new era of scaling brings both opportunities and complexities. The latest GPT APIs News suggests a move towards offering access to more specialized, powerful models. Instead of a one-size-fits-all API, we may see endpoints for models optimized for code generation (**GPT Code Models News**), creative writing, or data analysis. This trend also fuels the growth in GPT Custom Models News and GPT Fine-Tuning News, allowing businesses to adapt these massive base models to their specific needs. This is fostering a vibrant GPT Ecosystem News, with various GPT Platforms News and GPT Tools News emerging to simplify GPT Deployment News and GPT Integrations News.
The Dawn of Sophisticated GPT Agents
Perhaps the most exciting implication is the rise of autonomous agents. A key piece of GPT Agents News is that more efficient and powerful models are the brains that can power agents capable of complex, multi-step reasoning. These agents can interact with software, browse the web, and use tools to accomplish goals. For example, a marketing agent could be tasked with analyzing competitor trends, drafting a social media campaign using insights from GPT in Marketing News, generating visuals, and scheduling the posts, all with minimal human intervention. This represents a monumental leap from simple chatbots to proactive digital assistants.
Transforming Industries: From Healthcare to Finance
The applications of these scaled models are industry-agnostic and transformative:
- GPT in Healthcare News: Models can analyze medical literature, assist in drug discovery, and interpret diagnostic images with greater accuracy.
- GPT in Finance News: AI can perform sophisticated sentiment analysis on market news, build complex risk models, and detect fraudulent transactions in real-time.
- GPT in Legal Tech News: Systems can review thousands of documents for discovery, summarize case law, and draft initial contracts, augmenting the work of legal professionals.
- GPT in Content Creation News: The creative industries are being revolutionized, with AI assisting in writing scripts, composing music, and generating photorealistic images, pushing the boundaries of GPT in Creativity News.
The Double-Edged Sword: Challenges and Recommendations
With great power comes great responsibility. The very techniques that make models more capable also introduce a new set of challenges that must be addressed proactively.

Navigating the Pitfalls of Scale
The pursuit of scale is not without its risks. A primary concern in GPT Ethics News is that scaling can amplify the biases present in the vast **GPT Datasets News** used for training. MoE models, with their complex internal routing, can make it even harder to diagnose and mitigate these biases, a key topic in GPT Bias & Fairness News. Furthermore, as models become more powerful, the potential for misuse grows. This has spurred urgent conversations around GPT Safety News and the need for sensible GPT Regulation News to establish guardrails. Finally, the data-hungry nature of these models continues to raise important questions for GPT Privacy News, demanding robust data anonymization and protection protocols.
Best Practices for Responsible Scaling
Navigating this landscape requires a commitment to responsible development. This starts with meticulous data curation and cleaning to minimize bias from the outset. Continuous evaluation through red-teaming and comprehensive benchmarking is essential to understand a model’s limitations and failure modes. The debate around transparency is also central. While many cutting-edge models are proprietary, the GPT Open Source News community plays a vital role in fostering accountability and independent research. The dynamic between closed-source leaders and open-source challengers, a key part of GPT Competitors News, is crucial for a healthy, safe, and innovative ecosystem.
Conclusion: The Future is Smart, Not Just Big
The narrative around GPT scaling has matured. We are moving beyond the simple metric of parameter count and into an era of architectural elegance and computational efficiency. The latest GPT Trends News clearly indicates that techniques like Mixture of Experts, combined with sophisticated reinforcement learning and optimization methods, are the path forward. This intelligent scaling is unlocking unprecedented capabilities, from multimodal understanding to autonomous agents, that will redefine our interaction with technology.
The journey ahead, as we anticipate future developments like GPT-5, will be defined by this smarter approach. The ultimate goal is not just to build the largest model but the most capable, efficient, and aligned one. The GPT Future News will be written by those who can master this delicate balance, unlocking the immense potential of AI to solve real-world problems while diligently managing the associated risks.
Related Posts

Inside GPT Mixture-of-Experts Routing

Inside the BPE Tokenizer: How GPT Splits Words Into Subword Units
