
GPT Fine-Tuning News: How Specialized Models are Outperforming Giants like GPT-4
The New Frontier of AI: Why Smaller, Fine-Tuned Models are Achieving Superior Performance
In the rapidly evolving landscape of artificial intelligence, the dominant narrative has often been one of scale. The release of increasingly massive models, from GPT-3.5 to GPT-4 and the highly anticipated GPT-5, has suggested that bigger is unequivocally better. These large language models (LLMs) are marvels of general-purpose intelligence, capable of writing code, drafting legal documents, and creating poetry with remarkable fluency. However, recent GPT Fine-Tuning News reveals a compelling counter-narrative: for many specialized tasks, smaller, meticulously fine-tuned models are not just competing with—but are actively outperforming—their colossal counterparts. This shift signals a maturation of the AI ecosystem, where targeted expertise is becoming as valuable as raw, generalized power.
The latest developments in GPT Training Techniques News show that by training a more compact, open-source model on a narrow, high-quality dataset, developers and researchers can create a specialist AI. This specialist can capture nuances, understand domain-specific jargon, and avoid the inherent biases or knowledge gaps of a generalist model trained on the entire internet. This article explores this pivotal trend, breaking down how fine-tuning works, examining a real-world scenario where a smaller model identified critical insights missed by GPT-4, and providing actionable best practices for leveraging this powerful technique.
Section 1: The Generalist vs. Specialist Dilemma in Modern AI
The current AI landscape is largely defined by the tension between two development philosophies: creating all-encompassing generalist models and crafting highly specialized expert models. Understanding the strengths and weaknesses of each approach is critical for anyone looking to deploy AI effectively.
The Reign of the Generalists: The Power and Pitfalls of Scale
Models like GPT-4 represent the pinnacle of the scaling hypothesis. Trained on petabytes of diverse data from the web, books, and other sources, their strength lies in their versatility. This is the focus of much OpenAI GPT News and ChatGPT News. They can translate languages, summarize complex reports, and generate creative content without any task-specific training. This broad capability is powered by an immense number of parameters (rumored to be over a trillion in GPT-4’s case), which allows them to store and synthesize a vast amount of world knowledge. However, this generalization comes at a cost. Their knowledge is a mile wide but can sometimes be an inch deep. They may struggle with niche terminology, adopt a generic tone, or fail to grasp subtle, context-dependent nuances. Furthermore, their sheer size makes them computationally expensive to run, raising concerns about GPT Latency & Throughput News and overall GPT Efficiency News.
The Rise of the Specialists: Precision Through Fine-Tuning
Fine-tuning offers a powerful alternative. The process involves taking a pre-trained base model—often a smaller, open-source model like Mistral, Llama, or Phi—and continuing its training on a much smaller, curated dataset specific to a particular domain. This is akin to sending a general medical practitioner to a specialized fellowship to become a cardiologist. The foundational knowledge is already there; fine-tuning hones it for a specific purpose. The latest GPT Open Source News highlights a growing ecosystem of powerful base models perfect for this purpose. A fine-tuned model for legal tech can master the intricacies of contract law, while one for healthcare can learn to interpret clinical notes with greater accuracy. This approach not only yields superior performance on the target task but also results in smaller, more efficient models that are cheaper to deploy and can even run on edge devices, a key topic in GPT Edge News.
Section 2: Case Study Breakdown: Uncovering Nuance in Societal Impact Analysis
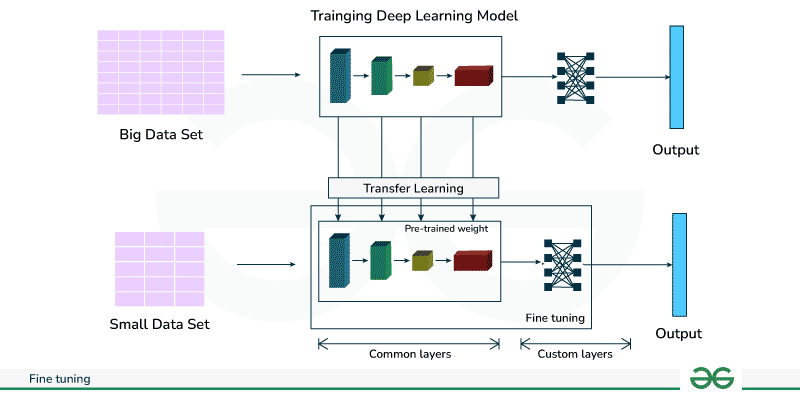
To illustrate the power of fine-tuning, consider the complex challenge of identifying and categorizing the negative societal impacts of AI as reported in the news. This is a task fraught with nuance, where a generalist model’s broad understanding might fall short. Recent GPT Research News provides a compelling blueprint for how specialization can triumph.
The Challenge: Capturing the Full Spectrum of AI’s Negative Impacts
A general-purpose model like GPT-4, when asked to analyze news articles for negative AI impacts, will perform reasonably well. It will likely identify obvious categories like job displacement, algorithmic bias, and privacy violations. However, its understanding is shaped by its vast but generic training data. It may miss subtle, emerging, or less-discussed categories of harm. For instance, it might lump “environmental impact from data centers” and “e-waste from AI hardware” into a single “Environmental” category, losing critical detail. It might overlook more nuanced psychological impacts, such as increased anxiety due to AI-driven surveillance or the de-skilling of creative professions. This is a classic blind spot for a generalist—it knows what is most prominent in its training data, but struggles with the long tail of specific, nuanced information, a critical focus of GPT Ethics News and GPT Bias & Fairness News.
The Fine-Tuning Solution: Building a Domain-Specific Expert
A research-driven approach demonstrates a more effective method. The process begins with creating a high-quality, specialized dataset. In this scenario, researchers would collect thousands of news articles specifically reporting on the negative consequences of AI. This dataset is the key. It’s not just a random scrape of the web; it’s a curated collection of domain-specific knowledge. Next, they select a capable but efficient open-source model, such as a 7-billion parameter model from the likes of Mistral. Using advanced GPT Training Techniques News, such as Low-Rank Adaptation (LoRA) for parameter-efficient fine-tuning, they train this model exclusively on the curated dataset of AI impact news. The model learns the specific language, patterns, and concepts unique to this domain.
The Result: Deeper Insights and Superior Categorization
When this newly fine-tuned specialist model is benchmarked against the generalist GPT-4 on the same task, the results are striking. The specialist model identifies a much wider and more granular range of impact categories. Where GPT-4 saw one “Environmental” category, the specialist might identify distinct categories for “Energy Consumption,” “Water Usage for Cooling,” “Carbon Footprint of Training,” and “Electronic Waste.” It can pick up on subtle impacts like “Algorithmic Homogenization of Culture” or “Erosion of Social Trust due to Deepfakes” that the generalist might miss entirely. This demonstrates a key takeaway from recent GPT Benchmark News: standard benchmarks may not capture the superior performance of specialized models on tasks that require deep domain expertise.
Section 3: Practical Implications and Best Practices for Implementation
The success of specialized models has profound implications for businesses and developers. It democratizes access to high-performance AI, moving beyond a reliance on a few providers of massive, one-size-fits-all models. However, successful implementation requires a strategic approach.
When to Fine-Tune vs. When to Use a General API
Deciding whether to fine-tune a model or use a general-purpose API (like those featured in GPT APIs News) is a critical first step.
- Fine-Tune When: You need to operate in a niche domain with specific jargon (e.g., GPT in Legal Tech News, GPT in Healthcare News), require a unique brand voice or style, need to correct for known gaps or biases in base models, or when cost-efficiency and low latency at scale are paramount.
- Use a General API When: Your tasks are broad and varied, you are in the rapid prototyping phase, you lack a high-quality dataset for fine-tuning, or the state-of-the-art performance of a model like GPT-4 is sufficient for your needs.

Best Practices for Creating High-Quality Datasets
The success of fine-tuning is almost entirely dependent on the quality of the training data. As the latest GPT Datasets News confirms, “garbage in, garbage out” is the rule.
- Source with Precision: Identify data sources that are highly relevant to your specific task. Avoid noisy, irrelevant data.
- Clean and Pre-process: Remove duplicates, correct errors, and standardize the format. The data should be clean and consistent.
- Structure for Success: Format your data in a way the model can easily learn from, typically using prompt-completion pairs. For a chatbot, this would be pairs of user questions and ideal bot answers.
- Ensure Diversity: Your dataset should cover a wide range of examples within your domain to prevent the model from overfitting and failing on unseen inputs.
Common Pitfalls and Advanced Techniques
Fine-tuning is not without its challenges. A primary risk is “catastrophic forgetting,” where the model loses some of its general abilities while learning the new task. Overfitting, where the model memorizes the training data instead of learning general patterns, is another major concern. To mitigate these, developers are turning to more advanced techniques discussed in GPT Optimization News. Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA freeze most of the base model’s weights and only train a small number of new parameters, significantly reducing computational cost and the risk of catastrophic forgetting. Other techniques like GPT Quantization News and GPT Distillation News focus on compressing the final model to improve GPT Inference News speeds and reduce deployment costs.
Section 4: The Future of AI: An Ecosystem of Interconnected Specialists
This trend towards specialization is reshaping the entire AI landscape, with significant implications for the future of development, deployment, and competition.

Democratizing AI and Fostering Competition
The rise of high-quality open-source models and efficient fine-tuning techniques is a democratizing force. It allows smaller companies, startups, and even individual developers to create GPT Custom Models News that can compete with, and in some cases surpass, the offerings of tech giants. This fosters a more vibrant and competitive GPT Ecosystem News, driving innovation across various sectors, from GPT in Finance News to GPT in Content Creation News. This shift empowers organizations to build AI solutions that are perfectly tailored to their unique needs, data, and privacy requirements, a key topic in GPT Privacy News.
Towards a Future of AI Agents and Orchestration
Looking ahead, the future of AI may not be a single, monolithic AGI but rather a collaborative ecosystem of specialized models. This aligns with emerging trends in GPT Agents News, where a primary “orchestrator” model could route tasks to the most appropriate specialist. For example, a user query might first be interpreted by a generalist model, which then delegates a legal question to a fine-tuned legal expert model and a coding question to a specialized GPT Code Models News expert. This modular approach combines the breadth of generalist models with the depth of specialists, creating a system that is more powerful, efficient, and robust than any single model could be on its own.
Conclusion: Expertise Trumps Scale in the New AI Paradigm
The latest GPT Trends News makes one thing clear: the era of “bigger is always better” is giving way to a more nuanced understanding of AI performance. While massive, general-purpose models like GPT-4 will continue to be foundational pillars of the AI world, the real competitive advantage for many applications will come from specialization. The ability to fine-tune smaller, more efficient models on high-quality, domain-specific data allows for the creation of true digital experts that can uncover insights, understand context, and deliver performance that even the largest models cannot match. As this trend accelerates, the focus will shift from simply accessing large models to strategically building and deploying custom-tailored solutions. The future of AI is not just about raw intelligence; it’s about focused, refined, and actionable expertise.


