
Architecting the Next Generation of AI: Integrating Redis, Python, and Large Language Models
Introduction
The landscape of artificial intelligence is shifting rapidly from static model interaction to dynamic, integrated system architectures. As we analyze the latest GPT Architecture News, it becomes evident that the true power of Large Language Models (LLMs) is not just in their standalone capabilities, but in how they are orchestrated within a broader technical stack. Developers and data scientists are no longer satisfied with simple prompt-response mechanisms; they are building complex ecosystems that leverage tools like Redis for memory management, Python for orchestration, and powerful APIs to create persistent, context-aware applications.

This evolution is driven by a surge in GPT Models News, particularly regarding the release of more efficient open-source alternatives and the continuous upgrades seen in GPT-4 News and GPT-3.5 News. The democratization of these technologies allows for the construction of sophisticated AI chatbots that possess long-term memory and low-latency responses. In this article, we will explore the architectural blueprints required to build these advanced systems, examining how OpenAI GPT News interacts with the broader world of database management and software engineering. We will delve into the critical role of memory storage, the efficiency of inference engines, and the future of GPT Agents News in automating complex workflows.
Section 1: The Modern AI Stack – Beyond the Model
The Convergence of Components
To understand the current state of GPT Ecosystem News, one must look at the modern AI stack. It is no longer sufficient to simply make an API call to a model. A robust AI application requires a “brain” (the LLM), a “memory” (Vector Databases or Stores like Redis), and a “nervous system” (Python/API glue code). Recent GPT Integrations News highlights a trend where developers are combining high-parameter models—such as GPT-J or proprietary engines—with fast, in-memory data structures.
Redis, for instance, has emerged as a critical component in this architecture. By utilizing Redis as a vector store or a session cache, developers can solve one of the most persistent issues in GPT Chatbots News: the lack of state. Standard LLMs are stateless; they do not remember previous interactions once the session closes. By architecting a system where Python scripts manage the flow of data between the user, the Redis database, and the GPT APIs News, developers create an illusion of continuous consciousness and context retention.
Open Source vs. Proprietary Architectures
A significant portion of GPT Open Source News focuses on the accessibility of models like GPT-J, Llama, and others available via platforms like Hugging Face. While ChatGPT News often dominates the headlines with its proprietary excellence, the open-source community is making strides in GPT Custom Models News. Building a chatbot with an open-source model allows for greater control over data privacy and infrastructure costs.
However, this comes with architectural challenges. GPT Competitors News suggests that while open models are catching up, deploying them requires robust hardware management. This is where GPT Hardware News becomes relevant. Running a 6-billion parameter model requires significant VRAM and optimized inference engines. Conversely, using an API-based approach (like OpenAI’s) offloads the compute burden but introduces dependency and latency variables. The choice between these architectures defines the scalability and cost-structure of the final application.
The Role of Python in Orchestration
Python remains the lingua franca of AI development. GPT Tools News consistently features Python libraries designed to streamline the interaction between LLMs and external data. Frameworks that facilitate “chaining” prompts or managing agents are essential. In a typical architecture, Python handles the logic: it receives the user input, queries the Redis database for relevant context (RAG), constructs a composite prompt, sends it to the model, and parses the response. This orchestration is central to GPT Platforms News, enabling the creation of applications that feel bespoke and intelligent rather than generic.
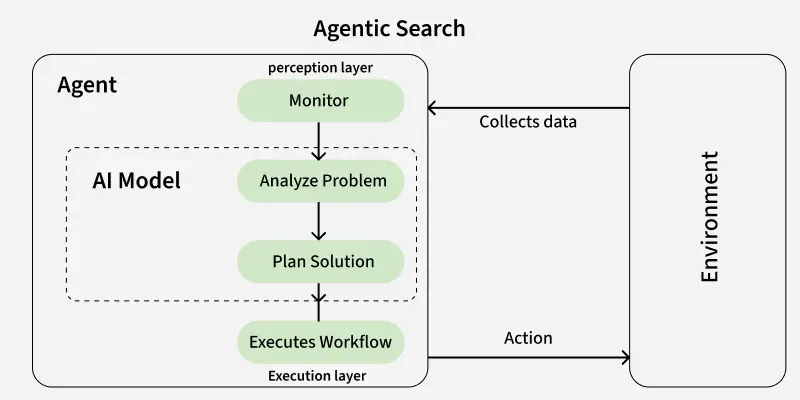
Section 2: Deep Dive into Architecture, Memory, and Optimization
Retrieval-Augmented Generation (RAG) and Vector Search
One of the most transformative concepts in GPT Research News is Retrieval-Augmented Generation (RAG). In a standard setup, the model relies solely on its training data, which leads to hallucinations or outdated information. By integrating a vector store (often powered by Redis or specialized databases), the architecture changes fundamentally. The system first retrieves relevant documents based on semantic similarity and feeds them into the model’s context window.
This approach touches upon GPT Datasets News and GPT Tokenization News. Efficient tokenization is crucial here because context windows are finite. If the retrieved context is too large, it truncates the prompt, leading to data loss. Recent GPT Optimization News suggests that better embedding models are reducing the dimensionality required to store concepts, making retrieval faster and more accurate. This architecture allows for GPT in Education News applications where a chatbot can tutor students based on a specific textbook without needing to retrain the model.
Latency, Throughput, and Inference
When building real-time applications, GPT Latency & Throughput News is a primary concern. A chatbot that takes ten seconds to reply breaks the user experience. GPT Inference News indicates that optimizing the “time to first token” is a priority for both hardware manufacturers and software engineers. Techniques such as GPT Quantization News—reducing the precision of the model’s weights from 16-bit to 8-bit or 4-bit—can drastically speed up inference with minimal loss in quality.
Furthermore, GPT Compression News and GPT Distillation News are gaining traction. Distillation involves training a smaller “student” model to mimic the behavior of a larger “teacher” model. For a specific task, such as customer support in GPT in Marketing News, a distilled model can perform just as well as a massive generalist model but at a fraction of the computational cost and latency. This is critical for GPT Edge News, where the goal is to run models on local devices or IoT endpoints.
Fine-Tuning vs. Context Injection
A common architectural debate found in GPT Fine-Tuning News is whether to fine-tune a model or use RAG. Fine-tuning alters the weights of the model to learn a specific style or domain knowledge. GPT Training Techniques News has evolved to include Parameter-Efficient Fine-Tuning (PEFT) and LoRA (Low-Rank Adaptation), which make this process cheaper. However, for factual consistency, RAG is often superior. A hybrid architecture often works best: using a fine-tuned model to understand the domain jargon (e.g., GPT in Legal Tech News or GPT in Healthcare News) while using RAG to fetch specific case files or patient records.
Section 3: Implications, Applications, and the Future Landscape
Multimodal Capabilities and Agents
The architecture of the future is not text-only. GPT Multimodal News and GPT Vision News are reshaping how we design chatbots. An advanced chatbot today might accept an image of a broken server rack, analyze the error lights using a vision model, query a technical manual via RAG, and output a Python script to fix the issue. This moves us into the realm of GPT Agents News—systems that can take autonomous actions based on reasoning.
In GPT in Finance News, an agentic architecture could autonomously monitor market trends, ingest news via API, perform sentiment analysis, and execute trades (within safety limits). This requires a complex architecture involving “tool use” where the model knows how to call external functions. GPT Code Models News plays a massive role here, as the model must generate syntactically correct code to interface with these external tools.
Scaling and Efficiency
As these systems scale, GPT Efficiency News becomes the headline. Running a chatbot for one user is easy; running it for a million users requires sophisticated load balancing and caching strategies. This is where the Redis integration mentioned earlier shines. By caching frequent queries, the system avoids expensive calls to the LLM. GPT Scaling News suggests that the future involves “Mixture of Experts” (MoE) architectures, where different parts of the model activate for different tasks, saving compute resources.
Global Reach and Language Support
The global nature of the internet demands GPT Multilingual News and GPT Cross-Lingual News. Modern architectures must handle input in one language, perhaps retrieve context stored in English, and generate a response in the user’s native tongue. GPT Language Support News indicates that newer models are showing emergent capabilities in low-resource languages, allowing for truly global GPT Deployment News.
Section 4: Pros, Cons, and Ethical Considerations
The Advantages of Modular Architecture
The shift toward component-based AI architecture (Python + Redis + LLM) offers immense flexibility. It avoids vendor lock-in, allows for the swapping of model backends as GPT Future News unfolds, and enables granular control over data. It facilitates GPT Applications in IoT News, where lightweight controllers can offload heavy reasoning to a central server while maintaining local state.
Challenges: Bias, Safety, and Regulation
However, with great power comes great responsibility. GPT Ethics News and GPT Bias & Fairness News are critical considerations. When a model is integrated into a banking or hiring workflow, architectural safeguards must be in place to prevent discriminatory outputs. GPT Safety News emphasizes the need for “guardrail” models—smaller, faster models that scan the input and output of the main LLM to filter out toxicity or sensitive data.
Furthermore, GPT Regulation News and GPT Privacy News are becoming major drivers of architectural decisions. In Europe, GDPR compliance might necessitate that no user data is sent to third-party APIs, forcing companies to adopt local, open-source GPT Inference Engines News. The “black box” nature of these models makes compliance difficult, pushing the industry toward more interpretable AI.
Best Practices for Developers
For those looking to build these systems, keeping up with GPT Trends News is vital.
- Sanitize Inputs: Always scrub user input before sending it to an LLM to prevent prompt injection attacks.
- Implement Caching: Use tools like Redis to cache identical queries. This saves money and reduces latency.
- Monitor Performance: Use GPT Benchmark News data to select the right model for the right task. You don’t need GPT-4 for simple classification tasks.
- Stay Updated: The field changes weekly. GPT 5 News is already generating buzz, and architectures built today must be adaptable for tomorrow’s models.
Conclusion
The journey from a simple script to a fully-fledged AI chatbot involves navigating a complex landscape of GPT Architecture News. By understanding the interplay between memory systems like Redis, orchestration layers like Python, and the raw reasoning power of models highlighted in OpenAI GPT News, developers can build systems that are not only intelligent but also scalable, efficient, and useful.
As we look toward a future filled with GPT Agents News and GPT Multimodal News, the importance of solid system architecture cannot be overstated. Whether it is for GPT in Creativity News, healthcare, or finance, the successful deployment of AI relies less on the magic of the model alone and more on the engineering that surrounds it. By adhering to best practices in safety, efficiency, and integration, we can harness these powerful tools to build the next generation of software.


