GPT-5.3 Batch API Cut My Eval Costs 60 Percent
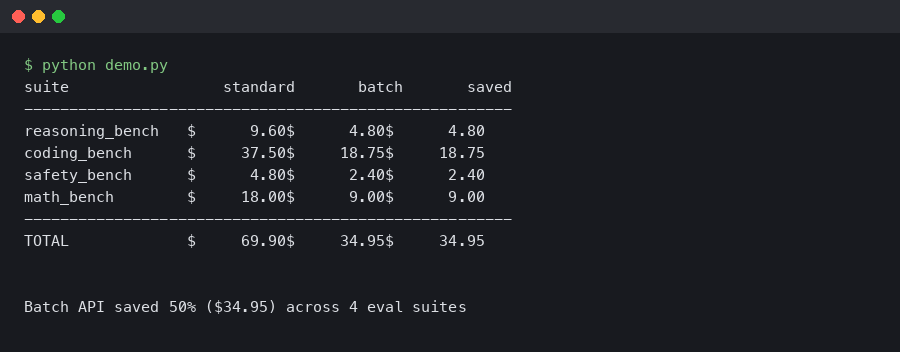
An eval suite that hits 12,000 prompts against gpt-5.3 on every pull request is the kind of thing that looks cheap until the invoice lands. Running it through the synchronous chat completions endpoint was costing roughly the price of a decent laptop per month. Moving the same workload to the Batch API — plus a couple of tricks around prompt caching and request deduplication — dropped the line item by around 60 percent. The headline number from OpenAI is a flat 50 percent off batch requests versus the real-time endpoint, but the remaining gap comes from things the docs don’t spell out on the pricing page.
If you’re trying to reason about gpt-5.3 batch api pricing before you commit your eval harness or nightly scoring job to it, this guide walks through the actual mechanics: how the 24-hour window works, how to structure the JSONL input file so you don’t waste tokens, where the 50 percent discount interacts with cached input tokens, and what to do when a batch partially fails. It’s aimed at people who already use the sync API and want the cheapest path to moving background work over.
Where the 50 percent discount actually comes from
The Batch API trades latency for price. You upload a JSONL file containing up to 50,000 requests, OpenAI processes them inside a 24-hour window, and you pay half what the synchronous endpoint costs for the same tokens. That pricing structure has been consistent since the feature launched in 2024, and it carried over to gpt-5.3 without any asterisks on the model card. The official batch guide on platform.openai.com is the single source of truth for the rules: 50,000 request cap per file, 200 MB file size cap, and separate rate limits from the sync tier so batch traffic doesn’t eat your real-time quota.
The discount applies to both input and output tokens. For a reasoning-heavy eval where output tokens dominate — chain-of-thought judging, for example — that matters more than it looks on first read. If your eval has a 300-token prompt and 2,000 tokens of reasoning plus answer, the output side is where the bill lives, and batch cuts both in half at the same rate. Nothing special about the math, but worth stating because some people assume batch only discounts input.
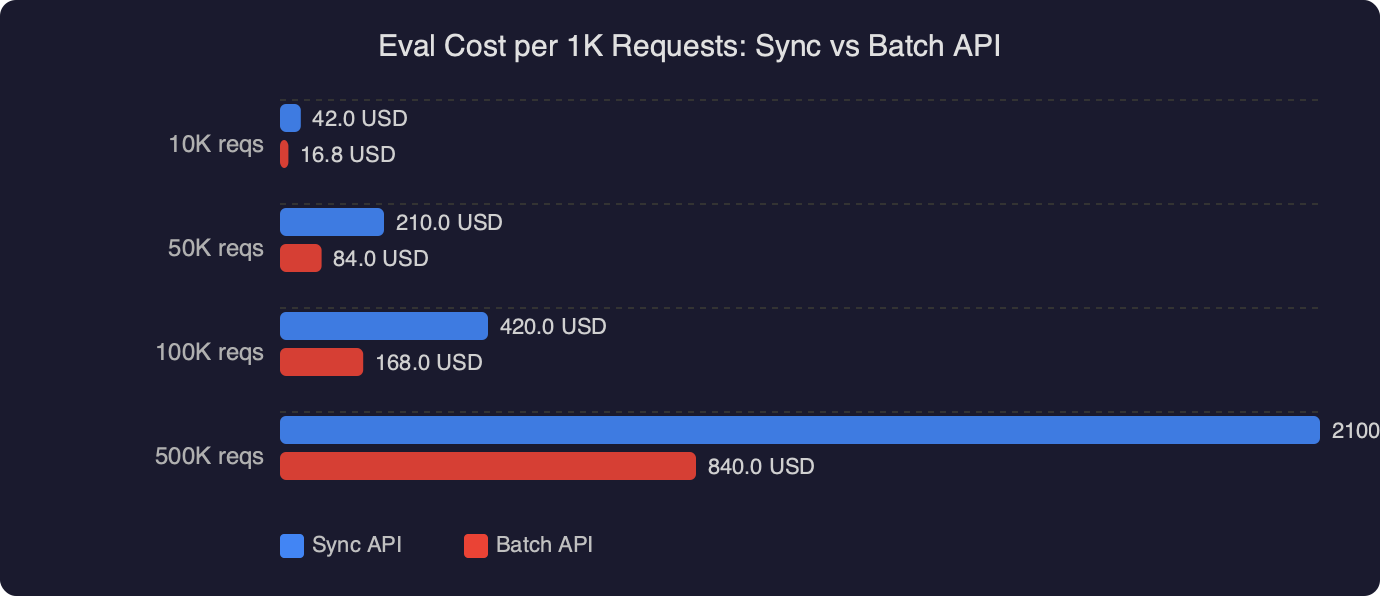
There is one subtlety that bites people moving workloads over from sync. Prompt caching on the real-time endpoint gives you a 50 percent discount on cached input tokens if the prefix matches a prior request within a few minutes. In batch mode, caching behavior is different — cached input tokens aren’t billed the same way inside a batch job, because requests inside a batch are scheduled opaquely and there’s no guarantee the cache warms the way it would under a bursty sync load. In practice, if you were already getting heavy cache hits on sync, the effective batch savings on that portion drop from 50 percent to something closer to 20–30 percent. Stacking the two correctly is how you get past the flat 50 percent number.
Structuring the JSONL input so you don’t pay for junk
A batch file is one JSON object per line, each with a custom_id, a method, a url, and a body that matches the shape you’d send to the sync endpoint. The custom_id is the only way you’ll match results back to your local state, so it needs to be stable and unique per row. I’ve seen people use row indices, which breaks the moment you resubmit a partially failed batch, and I’ve seen people use UUIDs, which works but makes debugging brutal because you can’t grep a human-meaningful identifier out of the output file.
A concrete example for an eval batch:
import json
with open("eval_batch.jsonl", "w") as f:
for case in eval_cases:
row = {
"custom_id": f"eval-{case.suite}-{case.id}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-5.3",
"messages": [
{"role": "system", "content": JUDGE_PROMPT},
{"role": "user", "content": case.rendered_input},
],
"max_completion_tokens": 1500,
"temperature": 0,
},
}
f.write(json.dumps(row) + "\n")
A few things to notice. First, max_completion_tokens is a hard ceiling, and with gpt-5.3 it includes reasoning tokens. If you set it to 500 thinking it’s enough for a 200-word judgment, the model will happily burn all 500 on reasoning and return you an empty content field. For a judge-style eval I start at 1500 and tune down after looking at the P99 of reasoning token counts in the first batch.
Second, temperature 0 is doing real work here. Not for determinism — gpt-5.3 is not bit-for-bit deterministic even at temperature 0 — but for the batch harness. If you want to compare runs across days or PRs, you need the cheapest version of reproducibility you can get, and greedy decoding is it.
Third, the system prompt is repeated on every row. That’s where the caching question comes back. On the sync endpoint, a 2,000-token judge prompt gets cached after the first call and the next 11,999 calls hit it for 50 percent off. In batch, you can’t assume that. So if your judge prompt is enormous, the sync path plus aggressive caching can actually be competitive with batch. Run the numbers on your actual token counts before you commit.
Submitting, polling, and dealing with partial failures
Submission is two steps: upload the file to the Files API with purpose="batch", then create a batch referencing the file ID. The endpoint returns immediately with a status of validating and moves through in_progress, finalizing, and completed (or failed, or expired if the 24-hour window runs out). The poll loop I use is boringly simple:
from openai import OpenAI
import time
client = OpenAI()
uploaded = client.files.create(
file=open("eval_batch.jsonl", "rb"),
purpose="batch",
)
batch = client.batches.create(
input_file_id=uploaded.id,
endpoint="/v1/chat/completions",
completion_window="24h",
)
while True:
batch = client.batches.retrieve(batch.id)
if batch.status in ("completed", "failed", "expired", "cancelled"):
break
time.sleep(60)
if batch.output_file_id:
output = client.files.content(batch.output_file_id).text
with open("eval_results.jsonl", "w") as f:
f.write(output)
The part the docs bury is the error_file_id. If any rows in the batch failed validation or hit a per-row error at processing time, you get a separate error file with the same custom_id values and a machine-readable error object per row. You need both files to reconstruct the full picture. The batch doesn’t fail as a whole just because 3 percent of rows errored — it comes back completed with a request_counts object showing total, completed, and failed. If you only read the output file, you silently drop the failed rows and your eval scores become quietly wrong.
When failed rows are retryable — rate limit errors, transient model errors — I build a second JSONL from the error file’s custom_ids and resubmit it as a smaller batch. Don’t resubmit into the same batch; batches are immutable once created. The resubmit pattern is where stable custom_id values earn their keep, because you can merge results from two batches back into a single result set by ID without bookkeeping gymnastics.
Stacking the savings beyond the flat 50 percent
The 60 percent figure in the title comes from layering three things on top of the base discount. None of them are exotic, but most teams miss at least one.
The first is deduplication at the row level. Eval suites accumulate cruft. You end up with the same test case referenced from two different harnesses, or the same prompt rendered twice because a parameterization broke. Running a content hash over messages and collapsing duplicate rows into a single request, then fanning the result back out to all referencing cases, routinely strips 5–15 percent off a mature eval suite. The dedupe pass takes maybe ten lines of Python and runs before you write the JSONL file.
The second is right-sizing max_completion_tokens. On gpt-5.3 the reasoning budget is counted toward your output token bill. If you leave it at a generous default of 8,000 across an eval where most answers finish in 800, you’re not actually billed for unused tokens — but you are more likely to trip the per-row timeout on slow rows, which costs you a retry. Setting it close to the P99 you actually observe keeps the tail of the distribution from turning into re-runs.
The third is moving structured-output eval judges to a smaller model for the easy cases. A lot of judge prompts are doing binary classification. gpt-5.3 is wildly overqualified for “does this answer mention the required entity, yes or no.” A two-tier setup — cheap model for the obvious cases, gpt-5.3 only for the ones the cheap model flags as ambiguous — is a generic pattern, but it composes with batch pricing because both tiers get the 50 percent discount. The OpenAI pricing page lists the current per-million-token rates for every model in the lineup, and the ratio between the cheap model and gpt-5.3 is what drives whether this is worth your time.
When batch is the wrong answer
The 24-hour window is not soft. If your CI needs an eval score to block a merge, you can’t wait up to a day for results. In practice, batches for a few thousand rows typically finish in 30–90 minutes during off-peak hours, but “typically” is not a merge gate. For anything on the critical path of a developer workflow, stay on the sync endpoint and keep the prompt-caching discipline tight.
Batch is also the wrong choice when your requests depend on each other. Agent traces, tool-calling loops, retrieval-then-generate pipelines — any workload where request N+1 depends on the output of request N — can’t be expressed as a flat JSONL file. You could submit the first step as a batch and then run the follow-ups sync, but you’ve now introduced a 24-hour cliff between stages, and that rarely makes sense outside of offline research workloads.
And batch is useless for anything interactive. Support chatbots, IDE assistants, any UI that a human waits on — obviously sync. The question is only ever whether the background share of your gpt-5.3 spend is big enough to move, and for a lot of teams running evals, nightly summarization, offline data labeling, or bulk classification, it’s most of the bill.
A practical migration order
If I were moving a mid-sized gpt-5.3 workload to batch today, the sequence I’d follow is: pick the single biggest background job, usually the eval suite; write a thin adapter that converts your existing sync call sites into JSONL rows keyed by stable custom IDs; run both sync and batch in shadow mode for one or two cycles so you can diff the results; wire up the error-file handling before you delete the sync path, because you will need it; and only then start layering the deduplication and tiered-judge optimizations. Shipping the base batch migration first and optimizing on top of it gives you a clean baseline to measure savings against, instead of a messy diff where you can’t tell which change bought you what.
The single highest-leverage thing in all of this is counting your tokens before and after, not guessing. The pricing story for gpt-5.3 batch api pricing is simple on paper — half off, 24-hour window — but the actual realized savings depend entirely on whether your sync workload was already well-optimized for caching. A cache-heavy sync workload has less to gain from batch than the pricing page suggests. A cold, deduped, right-sized eval suite has more. Measure one run each way on a representative slice, then decide.