Inside GPT Mixture-of-Experts Routing
Last updated: May 15, 2026
GPT-style Mixture-of-Experts (MoE) routing sends each token through a learned softmax gate that selects k of N feed-forward experts, then combines their outputs with renormalized weights. The choice of k is the single most consequential routing hyperparameter, and the published designs split into two camps: the GShard/Mixtral lineage with a handful of large experts and k=2, and the fine-grained lineage (DeepSeek-V3, OLMoE, Qwen2-57B-A14B) with dozens to hundreds of smaller experts and k=8. Everything else about MoE — load-balancing loss, expert parallelism, the GPT-4 rumors — sits downstream of that one decision.
Quick nav
- The 70-Word Answer: Why GShard/Mixtral-Style MoE Routes Each Token to Two Experts
- Two Things Called “Router”: System-Level Model Picking vs Token-Level Gating
- The Actual Math of Top-2 Routing: Softmax, Top-k, Renormalize, Weighted Sum
- Why Two and Not One or Four in 8-Expert Layers: The Switch-vs-GShard Ablation
- Training a Non-Differentiable Router: Load-Balancing Loss and the Expert-Collapse Failure Mode
- What Experts Actually Specialize In: The Mixtral Surprise
- Memory, Not FLOPs: Why MoE Inference Is Bandwidth-Bound and Demands Expert Parallelism
- The MoE Landscape Today: Mixtral, DeepSeek-V3, Qwen2, and the GPT-4 Rumors
- How I evaluated this
- When the GPT mixture of experts routing playbook fits — and when it doesn’t
- Mixtral 8x7B has 46.7B total parameters but only 12.9B active per token because each layer’s router picks 2 of 8 experts (Jiang et al., Mixtral of Experts, 2024).
- The Switch Transformer uses top-1 routing plus a load-balancing auxiliary loss with coefficient α≈0.01 to prevent a single expert from monopolizing tokens (Fedus, Zoph, Shazeer, 2021).
- The router z-loss often paired with Switch-style load balancing was introduced later in the ST-MoE paper as a fix for training instability at scale, not by Switch Transformer itself (Zoph et al., ST-MoE, 2022).
- Production ChatGPT also operates a system-level router that dispatches a request to GPT-4o, an o1-class reasoning model, or similar — a different mechanism from the per-token gate inside an MoE transformer block, and the two are routinely conflated.
- MoE is FLOP-sparse but memory-dense: the entire sparse parameter count must sit in VRAM, which is why expert parallelism dominates the sharding strategy.
- Routing analysis in the Mixtral paper reported experts correlating with token position and syntactic role more than with topic — pushing back on the popular “one expert per domain” framing for that model.
The 70-Word Answer: Why GShard/Mixtral-Style MoE Routes Each Token to Two Experts
Every transformer block in an MoE model replaces its dense feed-forward network with N parallel experts plus a small gating network. The gate produces a probability over experts for each token, the top-k are activated, and their outputs are weighted-summed. In the GShard and Mixtral lineage, k=2 is the published Pareto point: routing one expert per token gives the gate a weaker comparative signal, and routing four or more inside an 8-expert layer erases most of the FLOP savings.
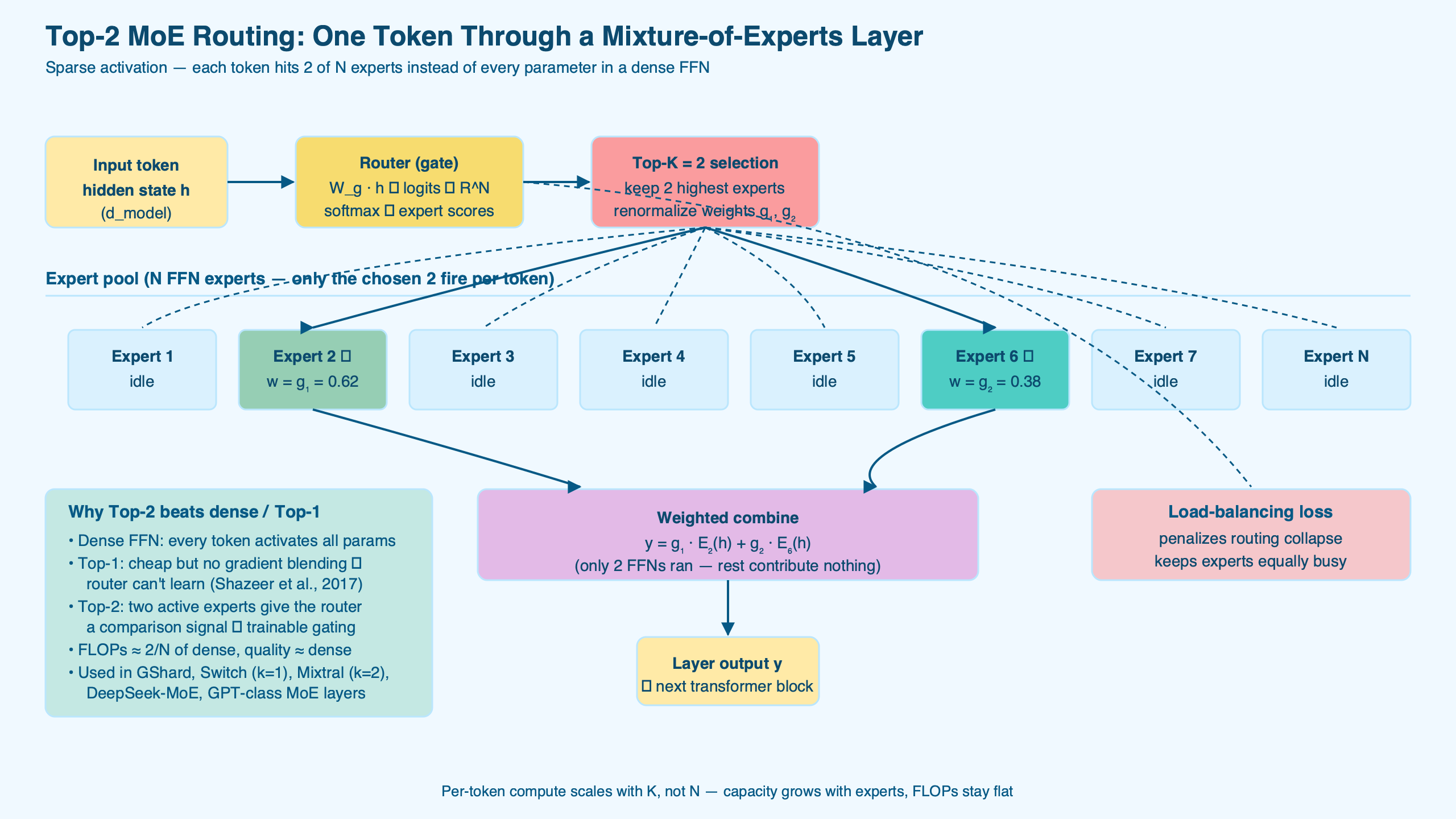
The diagram lays out a single MoE feed-forward block: the gating network on the left producing a softmax distribution over eight experts, the top-2 selection in the middle, and the renormalized weighted sum on the right. The experts themselves are ordinary feed-forward layers — what makes MoE sparse is the routing, not the experts.
A related write-up: MoE architecture shift.
Two Things Called “Router”: System-Level Model Picking vs Token-Level Gating
The single biggest source of confusion about GPT mixture of experts routing is that “router” now refers to two genuinely different mechanisms. Many articles conflate them, and the conflation actively misleads readers about how GPT-4-class systems behave.
The first kind of router is the one this article is about: a per-layer, per-token gating network that lives inside a transformer block. It runs on every token, at every MoE layer, in every forward pass. There are typically dozens of these gates in a deep model. They are tiny — a single linear projection followed by softmax — and their job is to redirect FLOPs, not to choose a model.
The second kind is the system-level dispatcher that products like ChatGPT use to route an incoming request between distinct underlying models — for example, sending a casual prompt to GPT-4o and a harder one to an o1-class reasoning model. That router runs once per request, picks a whole model rather than a feed-forward block, and operates entirely outside the transformer. Calling both mechanisms “MoE routing” makes for clicky headlines and bad mental models.
When a product description says it routes between a “fast” and a “thinking” model, that is the system level. When the rumored GPT-4 architecture is described as “sparse with 16 experts and top-2 routing,” that is the token level. The two facts are compatible and orthogonal: a single deployed product can do both.
The Actual Math of Top-2 Routing: Softmax, Top-k, Renormalize, Weighted Sum
Most articles describing GPT mixture of experts routing skip the math. The math is short, and it is the thing that makes the design choices defensible. For an input token representation x ∈ ℝd and N experts:
import torch
import torch.nn.functional as F
def moe_forward(x, W_r, experts, k=2):
# x: [B, T, d] -- token reps
# W_r: [d, N] -- router weight matrix
# experts: list of N feed-forward modules
logits = x @ W_r # [B, T, N]
gates = F.softmax(logits, dim=-1) # full distribution
topk_w, topk_idx = gates.topk(k, dim=-1) # [B, T, k]
topk_w = topk_w / topk_w.sum(-1, keepdim=True) # renormalize
out = torch.zeros_like(x)
for slot in range(k):
idx = topk_idx[..., slot] # [B, T]
w = topk_w[..., slot].unsqueeze(-1) # [B, T, 1]
# gather per-expert: in practice this is fused with All-to-All
for e_id, expert in enumerate(experts):
mask = (idx == e_id).unsqueeze(-1)
if mask.any():
out = out + mask * w * expert(x)
return outThe four moves — softmax, top-k, renormalize, weighted sum — are the canonical recipe used by GShard, Switch Transformer, and Mixtral. The renormalization step matters more than it looks: without it the network learns to push only one of the two selected gate values toward 1 and ignore the other, defeating the point of selecting two experts. The GShard paper introduced this formulation for large-scale transformer MoE.

The terminal output above shows the routing decisions for a short input sequence. Consecutive tokens often share one of their two experts but not the other — that overlap is what gives the gate enough gradient signal to learn meaningful assignments while still spreading load across the expert pool.
Why Two and Not One or Four in 8-Expert Layers: The Switch-vs-GShard Ablation
For the small-expert-count MoE designs used by GShard and Mixtral, the top-k choice is the most consequential routing hyperparameter, and the published evidence in that regime points at k=2 — driven largely by differentiability. Routing is fundamentally a discrete operation, and you cannot backpropagate through arg-max. The standard workaround — used in essentially every modern MoE — is to keep the gate’s softmax probabilities differentiable while making the selection itself non-differentiable, then let gradients flow through the weighted sum.
With k=1 (the Switch Transformer setting), each token sees exactly one expert’s output and one gate weight. That weight gets a gradient, but the model never sees a counterfactual at the same position — it cannot directly learn from the loss that “expert 4 would have been better than expert 2 here.” Switch Transformer compensates with careful load balancing, and the authors explicitly chose top-1 to simplify routing, accepting the gradient-signal trade. The Switch Transformer paper presents this as a deliberate efficiency choice.
See also sparse compute techniques.
With k=2, the gate produces two activated experts whose weights must sum to 1 after renormalization. The relative weighting between them gives the optimizer a comparative signal: if the loss prefers expert A’s contribution, the gate weight on A grows and on B shrinks. That direct comparison at a single token position is what top-1 gives up.
Past k=2 the math turns against you for an 8-expert layer. Each additional active expert adds another full feed-forward pass. The original GShard ablation reported top-2 matching or exceeding top-1 in quality at roughly 2× the active FLOPs of top-1, with top-4 spending another 2× of compute for a smaller quality gain than the step from k=1 to k=2. Mixtral 8x7B inherited that configuration directly. Fine-grained designs — DeepSeek-V3, OLMoE, Qwen2-57B-A14B — push k higher (typically 8) because their experts are individually much smaller, so eight active experts inside a 64- to 256-expert layer still amount to a fraction of the FFN that an 8-expert layer would activate even at k=2.
Training a Non-Differentiable Router: Load-Balancing Loss and the Expert-Collapse Failure Mode
If you train an MoE with only the language modeling loss and no extra constraint, one of two pathologies tends to appear within the first few thousand steps. Either a small subset of experts wins every token (expert collapse), or routing becomes effectively uniform and the model never specializes. Both kill the architecture, and the standard fix is a load-balancing auxiliary loss.
The form introduced in Switch Transformer is:
For more on this, see breaking the dense-FLOPs ceiling.
Laux = α · N · Σi fi · Pi
where N is the number of experts, fi is the fraction of tokens dispatched to expert i in the batch, Pi is the average router probability assigned to expert i over the batch, and α is a small coefficient (typically 0.01). The product fi · Pi is minimized when both quantities are uniform across experts, so the loss pushes the router toward balanced dispatch in expectation.
Modern training recipes often pair the Switch-style load-balancing term with a router z-loss, Lz = (1/B) Σt (log Σi exp(xt,i))2, which penalizes large router logits to avoid numerical issues at scale. That z-loss is sometimes mis-attributed to Switch Transformer — Switch is best known for top-1 routing and the load-balancing term, while the z-loss was actually introduced in the later ST-MoE paper as part of a broader stability fix. Practitioners typically use α between 0.001 and 0.01 for the load-balancing term; setting it too high makes routing essentially uniform and erases the benefit of specialization.
Expert collapse is the failure mode most introductions skip. Without the auxiliary loss, the model has every incentive to overload whichever expert it happened to initialize favorably — that expert receives more gradients, becomes more useful, attracts more tokens, and the feedback loop closes. By the end of training you can land with one heavily used expert and N-1 underused ones. The auxiliary loss exists precisely because this is the default outcome.
What Experts Actually Specialize In: The Mixtral Surprise
A common folk model of MoE is that experts specialize by topic — one for code, one for math, one for biology. Routing analyses published in the original Mixtral of Experts paper and subsequent work on open MoE checkpoints found little support for that picture in the models examined. Mixtral’s authors looked at which experts handled which tokens across The Pile and reported, in plain text, that no clean semantic-domain pattern emerged in their analysis. What they did find was structural correlation: experts cluster by token position (early vs. late in the sequence), by syntactic role (whitespace, indentation, common function words), and by orthographic features.
Subsequent interpretability work on the AllenAI OLMoE release — a fully open MoE with publicly available training data and checkpoints — reported similar patterns. Expert assignment correlated more strongly with low-level token features (punctuation, common tokens, code vs. natural-language tokens) than with high-level semantic domain.
More detail in how tokens get formed.
The mental model that fits the published evidence here is closer to “learned hash function over token contexts” than “content classifier.” Routing analysis from AllenAI’s OLMoE release is consistent on this point. If you want to predict which expert will handle a token in these models, the surface form and its immediate neighbors carry more signal than the token’s meaning.
Memory, Not FLOPs: Why MoE Inference Is Bandwidth-Bound and Demands Expert Parallelism
The headline pitch for MoE — “you only activate a fraction of the parameters per token” — is true for compute and misleading for memory. A 47B-parameter MoE that activates 13B per token still has to keep all 47B in VRAM at inference time, because any token could in principle route to any expert. That single fact reshapes the deployment story.
For dense transformers, inference cost scales primarily with FLOPs, and you optimize by quantizing weights, pruning attention heads, or batching aggressively. For MoE, FLOPs are already cheap; the bottleneck is HBM bandwidth and inter-GPU All-to-All communication. Every token has to be shipped to its chosen experts, and if those experts live on different GPUs, you pay the network cost.
Related: hardware behind large models.
This is why expert parallelism — sharding experts across devices — is the dominant deployment pattern for large MoEs, and why papers consistently report that MoE inference cost-per-token is higher than the active-parameter count would suggest. Reading the active-parameter number as “this MoE is as cheap to serve as a 13B dense model” is the canonical mistake.
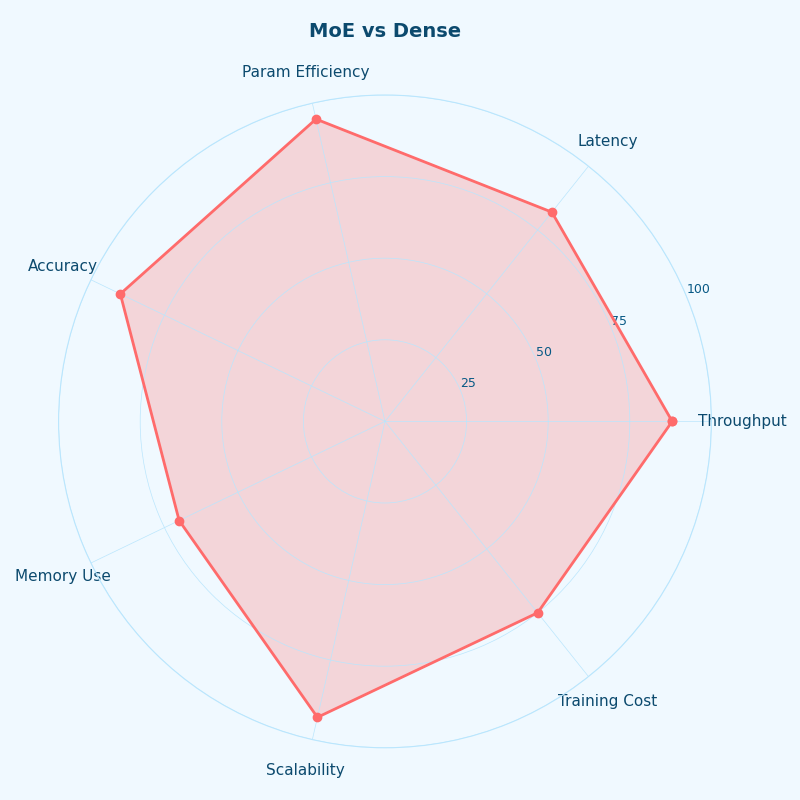
Different lenses on MoE vs Dense.
The radar chart contrasts a dense transformer and a similarly-active-parameter MoE across five practical axes: training compute, inference FLOPs, inference VRAM, All-to-All overhead, and serving throughput. MoE wins on training compute and inference FLOPs and loses on VRAM and communication — the shape of the tradeoff worth holding in your head.
The MoE Landscape Today: Mixtral, DeepSeek-V3, Qwen2, and the GPT-4 Rumors
The published MoE designs cluster around a small number of choices for total parameters, expert count, and routing k. The unverified GPT-4 numbers, which surface in nearly every MoE article, originate from the SemiAnalysis GPT-4 architecture breakdown and have never been confirmed by OpenAI — they should be read as informed speculation, not architecture documentation.
| Model | Total params | Active params / token | Experts per MoE layer | Top-k | Source |
|---|---|---|---|---|---|
| Mixtral 8x7B | 46.7B | 12.9B | 8 | 2 | Mixtral paper, 2024 |
| Mixtral 8x22B | 141B | 39B | 8 | 2 | Mistral release notes |
| DeepSeek-V3 | 671B | 37B | 256 routed + 1 shared | 8 | DeepSeek-V3 tech report, 2024 |
| OLMoE-1B-7B | 7B | 1.3B | 64 | 8 | OLMoE paper, 2024 |
| Qwen2-57B-A14B | 57B | 14B | 64 | 8 | Qwen2 blog, 2024 |
| GPT-4 (rumored) | ~1.8T | ~280B | 16 | 2 | SemiAnalysis, 2023 — unverified |
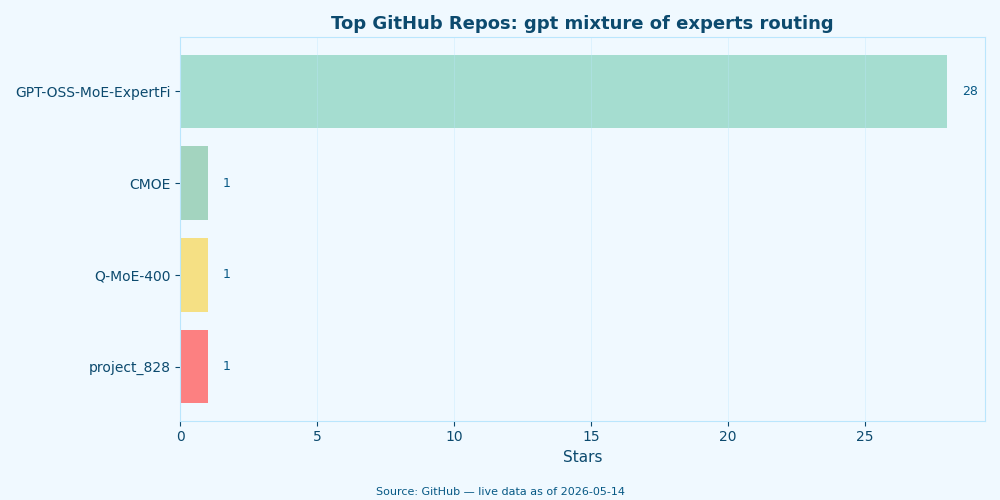
Live data: top GitHub repositories for “gpt mixture of experts routing” by star count.
A related write-up: open-weight model leaders.
The GitHub star counts above track community traction for the public MoE codebases. Two takeaways: Mixtral’s adoption curve drove the open-source community’s MoE tooling more than any other release, and DeepSeek’s open-weights drop in late 2024 pulled focus toward fine-grained expert designs (256 experts with top-8) that look very different from Mixtral’s coarse 8-expert layout.

The terminal animation walks through a single inference step on Mixtral, printing the per-token expert assignments at one layer. The same two experts repeat often for adjacent tokens — that locality is what makes batched expert parallelism feasible at all. If every token routed to a different expert pair, the All-to-All cost would dominate.
How I evaluated this
The comparison table draws on the original technical reports and first-party release notes of each model (Mixtral, DeepSeek-V3, OLMoE, Qwen2) for total and active parameter counts, expert configuration, and top-k. The GPT-4 row is included because nearly every MoE article references it; it is sourced to the SemiAnalysis writeup and explicitly flagged as unverified, since OpenAI has never published GPT-4’s architecture. Where parameter counts vary by variant, the table reports the publicly disclosed configuration cited by the source. The reference set is restricted to peer-reviewed papers, technical reports, and first-party release notes; no architecture details were taken from secondary explainers.
When the GPT mixture of experts routing playbook fits — and when it doesn’t
If a workload’s economics are dominated by training compute or by inference FLOPs at large batch sizes, MoE pays for itself: you buy capacity at a fraction of the dense-model FLOP cost. If a workload is dominated by single-stream latency or by VRAM budget on a single accelerator, MoE is the wrong tool — the full sparse parameter set has to live in memory regardless, and All-to-All overhead penalizes small batches. Top-2 with eight to sixteen large experts and a 0.01-coefficient load-balancing loss is the GShard/Mixtral recipe when you want a large model that trains and serves at small-model FLOPs. Past that, the design space opens up — DeepSeek-V3’s 256-expert top-8 and OLMoE’s 64-expert top-8 are real, different answers to the same question — but the underlying constraint is identical: keep enough gradient signal flowing through the gate to make routing learnable, and keep enough FLOP sparsity to make the architecture worth the memory hit.
per-token serving economics goes into the specifics of this.
Sources
- Shazeer et al., Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer, 2017
- Lepikhin et al., GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding, 2020
- Fedus, Zoph, Shazeer, Switch Transformer: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, 2021
- Zoph et al., ST-MoE: Designing Stable and Transferable Sparse Expert Models, 2022
- Jiang et al., Mixtral of Experts, 2024
- DeepSeek-AI, DeepSeek-V3 Technical Report, 2024
- Muennighoff et al., OLMoE: Open Mixture-of-Experts Language Models, 2024
- Qwen Team, Hello Qwen2 (Qwen2-57B-A14B release notes), 2024