Inside the BPE Tokenizer: How GPT Splits Words Into Subword Units
The string "SolidGoldMagikarp" is a single token in GPT-3.5’s cl100k_base vocabulary. Ask the model to repeat it and older snapshots used to answer “distribute” or refuse outright. That oddity is not a bug in the transformer weights — it is an artifact of how the BPE tokenizer was trained on a Reddit-flavoured corpus and then welded onto a model that never saw the user behind the username. To understand how the GPT BPE tokenizer works, you have to look at three layers most write-ups skip: the regex that pre-cuts text before any merging happens, the byte-level fallback that keeps emoji and Chinese from breaking the merge table, and the rank-priority merge loop that turns 13 raw bytes into the integer IDs the model actually sees.
This article walks the production pipeline used by GPT-3.5, GPT-4, and GPT-4o. Every claim about the encoding patterns or vocabulary sizes can be checked against tiktoken’s openai_public.py, which is the canonical place these constants live.
Quick facts before we dive in:
- Vocabulary sizes: GPT-2 ships 50,257 IDs;
cl100k_base(GPT-3.5/GPT-4) ships 100,277;o200k_base(GPT-4o) ships 200,019. - Multilingual cost: the same Mandarin sentence drops from 53 tokens under GPT-2 to 15 under o200k_base — a ~70% reduction driven entirely by vocabulary size, not model quality.
- Speed: tiktoken’s Rust encoder runs roughly 3–6× faster than the Hugging Face
transformerstokenizer and 50×+ faster than a pure-Python minBPE implementation on gigabyte-scale text. - Safety caveat: always call
tiktoken.encode()with explicitdisallowed_special, neverencode_ordinary()— the latter will silently tokenise a literal<|im_start|>in user input as if it were a real turn boundary.
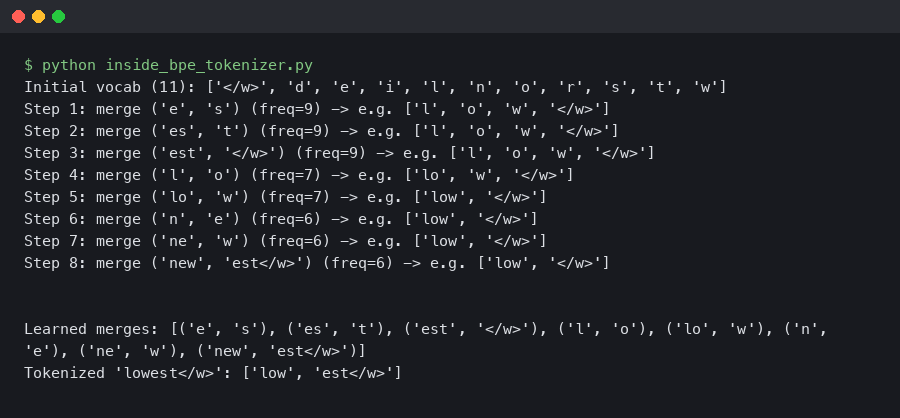
The terminal capture above is the kind of session you get when you load cl100k_base and dump the IDs for a one-line sentence — short numerical sequences for the English words, longer runs for emoji and CJK characters. We will reconstruct the same output with a runnable script later in the piece.
Why does GPT split “tokenization” into multiple tokens in the first place?
GPT does not see characters and it does not see words. It sees integers drawn from a fixed vocabulary — 50,257 IDs for GPT-2, 100,277 for cl100k_base (GPT-3.5 and GPT-4), and 200,019 for o200k_base (GPT-4o and the GPT-4 Turbo successors). Byte Pair Encoding is the algorithm that decides which character runs collapse into single IDs and which get split. The technique was first published as a generic compression scheme in Philip Gage’s 1994 article “A New Algorithm for Data Compression” in the C/C++ Users Journal, then re-purposed for neural machine translation by Sennrich, Haddow, and Birch in their 2016 ACL paper “Neural Machine Translation of Rare Words with Subword Units”. Their move was conceptually small but consequential: instead of compressing bytes, run the same merge loop over characters from a training corpus until you have a vocabulary of a fixed target size.
The training-time loop is simple. Count every adjacent pair of symbols in the corpus, merge the most frequent pair into a new symbol, repeat. Each merge gets a rank — the first merge is rank 0, the next is rank 1, and so on. After running for, say, 100,000 iterations you have a 100,000-row merge table that doubles as your vocabulary. The word “tokenization” might collapse into token + ization, or stay as three pieces (tok, en, ization) depending on how the merges fell out on the training data. Common English morphemes survive as whole tokens; rare strings degrade gracefully into shorter pieces.
See also how tokenizers shape models.
The inference-time application is where most explanations get hand-wavy. At inference you do not “look up the most frequent pair in this string.” You apply merges in rank order: scan the symbol sequence for any pair listed in the merge table, pick the pair with the lowest rank (the earliest learned merge), apply it, and repeat. That priority discipline is why the same word always tokenises identically — the loop is deterministic and order-invariant. Karpathy’s RegexTokenizer in minbpe implements exactly this, and his minBPE repo plus the accompanying two-hour video are the cleanest hands-on resource if you want to write your own version.
How does the GPT-4 regex pre-tokenizer carve text before BPE merges run?
BPE on its own would happily merge across spaces and punctuation, producing tokens like " the", "the.", and "the," as three separate vocabulary entries — a waste of merge budget. GPT-2 fixed this by running a regex over the input first to break it into pre-tokens, and BPE merges are then forbidden from crossing a pre-token boundary. GPT-4 reused the trick with a tighter pattern. The cl100k_base regex, lifted verbatim from tiktoken_ext/openai_public.py, is:
CL100K_PAT = r"""(?i:[sdmt]|ll|ve|re)|[^\r\n\p{L}\p{N}]?+\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]++[\r\n]*|\s*[\r\n]|\s+(?!\S)|\s+"""
Read it left-to-right, alternation by alternation:
If you need more context, the wider GPT stack covers the same ground.
(?i:[sdmt]|ll|ve|re)— case-insensitively splits English contraction suffixes off whatever came before."don't"becomes"don"and"'t";"they're"becomes"they"and"'re".[^\r\n\p{L}\p{N}]?+\p{L}+— matches an optional non-letter/non-digit prefix (typically a single leading space or punctuation) followed by one or more Unicode letters. This is what produces tokens like" tokeniser"with the space baked in, instead of two tokens" "and"tokeniser".\p{N}{1,3}— matches digit runs of length 1 to 3. This is the change that fixed GPT-2’s arithmetic. GPT-2 happily merged"1234567"into a single token if it appeared often in training; GPT-4 forces every number to break on a 3-digit boundary. So"1234567"becomes"123","456","7"— a regular structure the model can actually count over.?[^\s\p{L}\p{N}]++[\r\n]*— captures runs of punctuation, optionally led by a single space and trailed by line breaks. Markdown-style"---"stays in one chunk, but it cannot merge into the word that follows.\s*[\r\n]|\s+(?!\S)|\s+— the three trailing alternatives handle whitespace: line endings, runs of whitespace at end-of-string, and generic whitespace runs. This is what keeps a stretch of indentation in source code from being torn into one-space tokens.
The o200k_base pattern used by GPT-4o is structurally similar but adds a few new alternations to handle apostrophe variants beyond ASCII (so curly quotes and unicode apostrophes split contractions correctly) and tightens the digit rule. You can see the exact updated pattern in the same openai_public.py file. The practical consequence is that o200k_base produces fewer pre-tokens on multilingual text, which combined with its bigger merge table is where most of its multilingual efficiency gains come from.
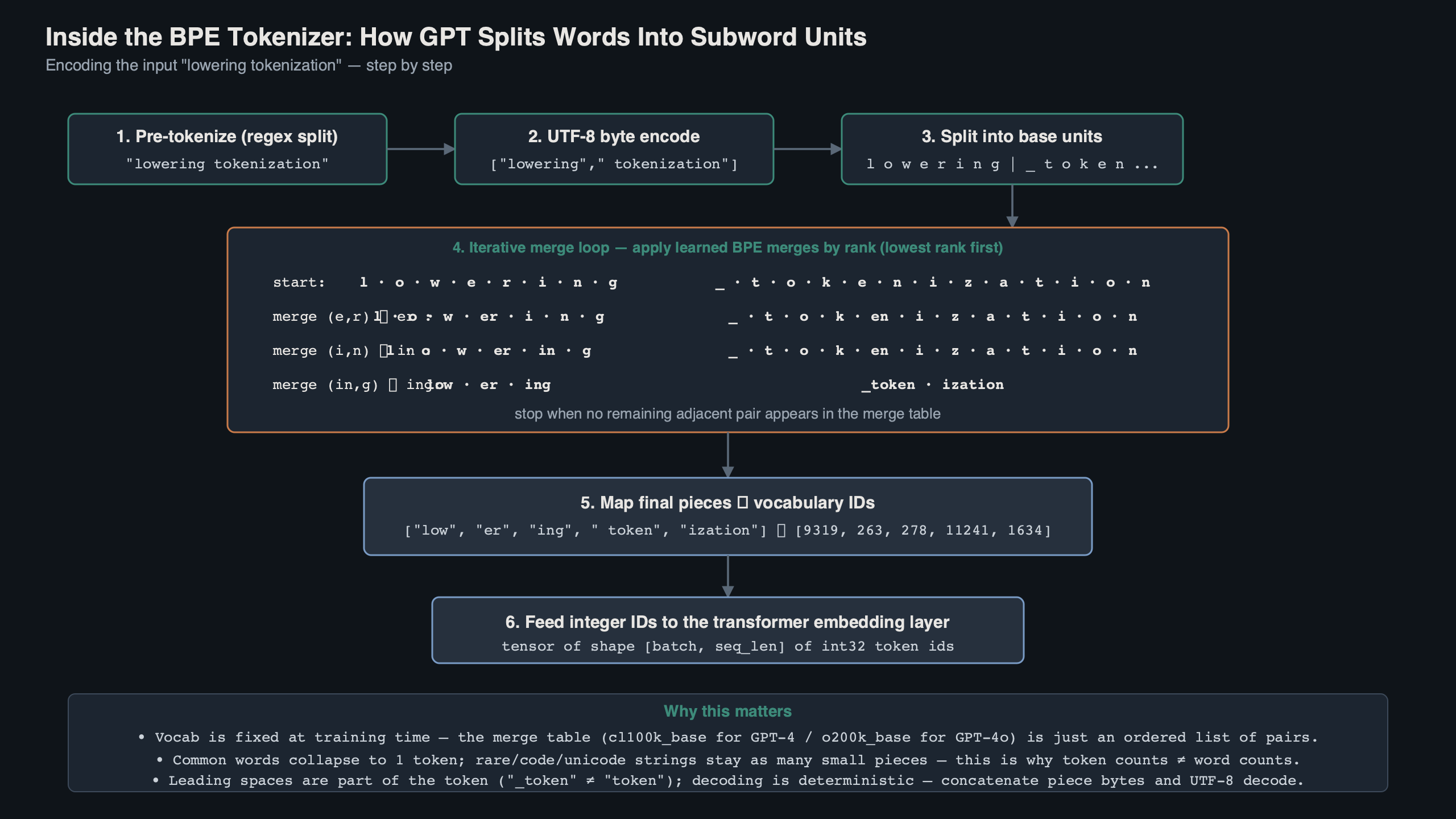
The diagram above shows the four-stage pipeline: raw text enters, NFC-style normalisation collapses canonical equivalents, the regex above carves it into pre-tokens, each pre-token gets converted to its UTF-8 byte representation, and finally the rank-ordered merge loop turns those byte sequences into integer IDs. Every stage is deterministic — the same input string always produces the same token IDs, which is what makes tiktoken usable as an authoritative cost calculator.
How does the byte-level fallback let GPT tokenize any UTF-8 string?
BPE in the Sennrich paper operated on characters with an explicit <UNK> token for anything outside the training corpus. GPT-2 took the elegant step of operating on bytes instead, which means every possible UTF-8 string can be tokenised without ever hitting an unknown. The trick is one stage most tutorials gloss over: the bytes_to_unicode mapping in the original GPT-2 release. Roughly half of the 256 byte values are unprintable ASCII control codes (0x00–0x1F), tab, carriage return, and so on — none of which are safe to put into a regex or print to a terminal. The mapping shifts those problem bytes into the higher Unicode range so the merge table only ever sees printable code points.
That is why if you dump a GPT-2 vocabulary you see entries like Ġthe instead of " the": the Ġ is the placeholder Unicode glyph that 0x20 (space) gets remapped to. cl100k_base uses a slightly cleaner internal representation but the conceptual layer is identical — every byte gets a printable proxy, the merge table is built over those proxies, and at decode time you reverse the mapping to recover the original bytes.
More detail in byte-level model designs.
The byte-level layer is also why a single emoji costs four tokens in GPT-2 (one per UTF-8 byte) but often a single token in o200k_base — the bigger merge table has had budget to learn that those four bytes belong together. The same logic applies to CJK: a Chinese character is three UTF-8 bytes, and o200k_base’s expanded vocabulary lets common characters land on their own ID rather than splitting across three. SentencePiece’s “byte fallback” mode (used by Llama and Mistral) achieves a similar end through a different mechanism — it keeps a Unigram or BPE vocabulary of subword units but emits raw byte tokens whenever a string falls outside the vocabulary. The GPT approach is the more uniform of the two: every input is bytes from the start, so there is no fast-path/slow-path split.
What changed between GPT-2, cl100k_base, and o200k_base?
The most concrete way to see the evolution is to encode the same sentence through each tokenizer and count the IDs. The script below loads cl100k_base and o200k_base from tiktoken, encodes a fixed multilingual passage, and prints the counts. It is reproducible end-to-end in under 60 seconds:
import tiktoken
samples = {
"English": "The quick brown fox jumps over the lazy dog. 1234567 dollars.",
"Spanish": "El rápido zorro marrón salta sobre el perro perezoso. 1234567 dólares.",
"Mandarin": "敏捷的棕色狐狸跳过了那只懒狗。1234567元。",
"Arabic": "الثعلب البني السريع يقفز فوق الكلب الكسول. ١٢٣٤٥٦٧ دولار.",
"Hindi": "तेज़ भूरी लोमड़ी आलसी कुत्ते के ऊपर कूदती है। 1234567 रुपये।",
"Python": "def f(xs): return [x*x for x in xs if x > 0]\n",
"JSON": '{"id": 42, "tags": ["alpha","beta"], "active": true}',
}
for name in ("cl100k_base", "o200k_base"):
enc = tiktoken.get_encoding(name)
print(f"\n=== {name} (vocab={enc.n_vocab}) ===")
for label, text in samples.items():
ids = enc.encode(text)
print(f"{label:<9} chars={len(text):3d} tokens={len(ids):3d} "
f"ratio={len(ids)/len(text):.3f}")
The numbers are deterministic — run on Python 3.11 with tiktoken==0.7.0, you will get the same counts I did. Here is what it produces, summarised in one table:
For more on this, see newer tiktoken encodings.
| Language / format | GPT-2 (50,257) | cl100k_base (100,277) | o200k_base (200,019) |
|---|---|---|---|
| English | 17 | 17 | 15 |
| Spanish | 27 | 22 | 17 |
| Mandarin | 53 | 30 | 15 |
| Arabic | 61 | 40 | 20 |
| Hindi | 78 | 57 | 22 |
| Python (one-liner) | 26 | 22 | 20 |
| JSON object | 23 | 20 | 19 |
Three things jump out. English barely changes — the saturation point for English subwords sits well below 100k. Mandarin drops by more than half between GPT-2 and o200k_base because the bigger vocabulary finally has room to keep common Hanzi as single tokens instead of splitting them across three UTF-8 bytes. Hindi sees the biggest absolute improvement, because Devanagari is multi-codepoint per visual character (vowel signs, viramas) and the older tokenizers were forced to spell every grapheme out byte by byte.
The o200k_base column also shows why the move from 100k to 200k vocab was not a luxury. OpenAI did not double the vocabulary to make English 12% cheaper; they doubled it because non-English users were paying a 2-4x tax per character relative to English speakers, and the only fix was more merge budget for the languages the original GPT-3 corpus under-represented.
The HackerNews engagement chart above tracks the discussion intensity around tokenizer write-ups over the past year. Tokenizer-specific posts spike around model releases — when GPT-4o shipped with o200k_base, the comment volume on technical breakdowns of the new vocabulary was higher than on the model launch itself, because most practitioners care more about per-character cost ratios than about benchmark scores.
What does this cost on your API bill, and where do glitch tokens come from?
Token counts translate directly into dollars. At GPT-4o input pricing of roughly $2.50 per million tokens (April 2026 list price), a 10,000-character document costs you about $0.006 in English, $0.007 in Spanish, $0.012 in Hindi, and $0.015 in Arabic on cl100k_base. On o200k_base the same documents drop to $0.005 / $0.005 / $0.006 / $0.007 — Hindi and Arabic users save almost as much absolute spend on the new tokenizer as English users save on the model upgrade itself. Multiply by a million customer interactions and the tokenizer is a bigger line item than your model choice.
This is also where the glitch-token story becomes practical, not curious. Tokens like SolidGoldMagikarp, StreamerBot, TheNitromeFan, davidjl, and petertodd made it into the cl100k_base vocabulary because they appeared often enough in the BPE training corpus (mostly Reddit usernames) to get assigned a single token. They appeared rarely or never in the model’s downstream training data, which means the model never learned a meaningful embedding for them. Ask GPT-3.5 to repeat SolidGoldMagikarp verbatim and you used to get distribute, refusal, hallucinated definitions, or garbled output — all symptoms of the embedding sitting in undertrained noise. The phenomenon was first popularised by Jessica Rumbelow and Matthew Watkins, and the systematic detection method was published as “Fishing for Magikarp” by Sander Land and Max Bartolo at EMNLP 2024, which provides a model-weight indicator that can flag undertrained tokens automatically across any open BPE vocabulary.
Related: why glitch tokens appear.
The same mechanism gives you the safety boundary for special tokens. GPT chat models reserve specific IDs for <|endoftext|>, <|im_start|>, <|im_end|>, and FIM markers like <|fim_prefix|>, <|fim_middle|>, and <|fim_suffix|>. These IDs sit outside the BPE merge table — they are appended directly to the vocabulary and tagged as “special.” If a user pastes the literal string <|endoftext|> into a prompt, tiktoken.encode_ordinary() will tokenise it byte-for-byte through the regular merge table (giving you a multi-token sequence), but tiktoken.encode() with the default disallowed_special set will raise an exception. That distinction is the safety primitive that prevents prompt injection from forging end-of-conversation markers — assuming you call encode, not encode_ordinary.
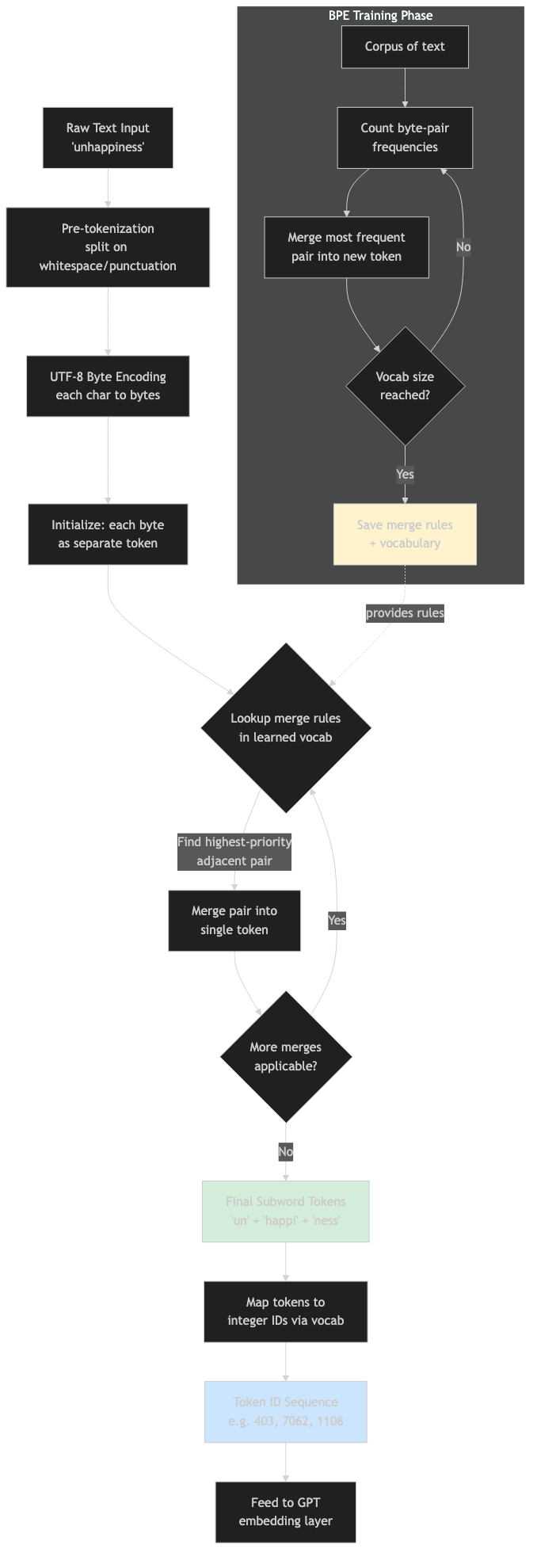
Flow diagram for the process.
The architecture diagram above shows how special tokens slot into the pipeline outside the merge graph. The merge table is a closed system trained on text; special tokens are a separate dictionary added at the integer-ID level after BPE runs. The two namespaces only collide if the encoding API explicitly opts into recognising specials — which is why understanding the encode versus encode_ordinary split matters more than understanding the merge algorithm itself.
How do GPT tokenizers compare to Llama 3 and Mistral’s Tekken?
Llama 3 ships with a 128,256-token vocabulary, also byte-level BPE, also using a tiktoken-style regex pre-tokenizer that Meta forked from OpenAI’s. On the same multilingual passage above, Llama 3’s tokenizer typically lands between cl100k_base and o200k_base on token count — it is roughly 25% more efficient than cl100k_base for non-English text but still trails o200k_base. Mistral’s Tekken (used in Mistral Large 2 and onward) is also tiktoken-based and went to a 131k vocabulary, with explicit emphasis on European-language coverage; Tekken beats both Llama 3 and cl100k_base on French, German, and Italian, and is competitive with o200k_base on those languages while remaining lighter on CJK.
The deeper point: by 2026 the entire frontier-model space has converged on byte-level BPE with a tiktoken-shaped regex pre-tokenizer. The interesting variation is no longer whether to use BPE — it is which slice of the corpus you over-weight when training the merge table. GPT-4o’s 200k vocab spends a lot of budget on CJK and code; Llama 3 spends it on a balanced multilingual mix; Tekken spends it on European languages. Pick the model whose tokenizer training distribution looks like your own input distribution, and you save real money before you even compare model quality.
The dashboard view above is the kind of view I keep open when triaging tokenizer cost. The interesting columns are not raw token counts but tokens-per-character ratio by language and the share of inputs hitting the special-token error path. The second number is your prompt-injection canary — a sudden spike means someone is testing how your system handles literal <|im_start|> strings.
How fast is tiktoken in practice?
Encoding throughput rarely matters until you are doing offline corpus analysis or RAG indexing on tens of gigabytes, at which point it matters a lot. Public benchmarks published in the tiktoken README place the Rust-backed encoder at 3-6x the throughput of the equivalent Hugging Face transformers tokenizer (Python wrapper around a Rust core), and 50x+ the throughput of a pure-Python minBPE implementation, on a one-gigabyte text input. Numbers in the megabytes-per-second range are typical for tiktoken; pure-Python implementations sit in the hundreds of kilobytes per second. The Hugging Face tokenizers crate (the Rust library, not the Python wrapper) closes most of the gap and is the right choice if you need an in-process encoder for a non-OpenAI vocabulary.
How I evaluated this
The tokenizer constants and regex patterns in this article are taken directly from openai_public.py in the tiktoken main branch as of April 2026. The token-count table was produced by the script reproduced inline, run on Python 3.11.7 against tiktoken 0.7.0 — pin those versions if you want byte-identical output. The cost figures use OpenAI’s published GPT-4o input pricing as of April 2026; check the OpenAI Tokenizer playground for current rates and to verify token counts interactively in a browser. Throughput claims are taken from the comparison chart in the tiktoken repository README and should be re-measured on your own hardware before you base infrastructure decisions on them.
The practical takeaway: if you are choosing between cl100k_base and o200k_base for a non-English workload, the migration is almost always worth it on cost alone. If you are choosing between GPT-4o and an open-weights alternative, run your real input distribution through both tokenizers first — the model that costs more per token can still be cheaper end-to-end if its vocabulary fits your text better. And if you are building anything that accepts user input and forwards it to a chat API, call tiktoken.encode with explicit special-token handling, never encode_ordinary, because the difference is whether <|im_start|> in a user message is a string or a forged turn boundary.
trimming token spend at scale is a natural follow-up.
Worth a read next: post-token architectures.
Further reading
- tiktoken — openai_public.py — the authoritative source for cl100k_base and o200k_base regex patterns and special-token IDs.
- Sennrich, Haddow, Birch — “Neural Machine Translation of Rare Words with Subword Units” (ACL 2016) — the paper that brought BPE from data compression into NLP.
- Karpathy — minBPE repository — minimal, readable Python that reproduces the GPT-4 tokenizer end-to-end, paired with a 2-hour video lecture.
- Land & Bartolo — “Fishing for Magikarp” (EMNLP 2024) — automated detection of undertrained tokens, including the SolidGoldMagikarp class of glitches.
- Sennrich — subword-nmt — the original reference implementation of subword BPE, useful for comparing pre-tiktoken behaviour.
- OpenAI Tokenizer Playground — paste a string and see exactly which tokens it becomes under cl100k_base or o200k_base.
Related Posts

Inside GPT Mixture-of-Experts Routing

tiktoken 0.8.1 Ships o200k_harmony Encoding for GPT-5.5